Intel's Interconnected Future: Combining Chiplets, EMIB, and Foveros
by Dr. Ian Cutress on April 17, 2019 8:00 AM EST
While Intel works on getting its main manufacturing process technology on track, it is spending just as much time and effort in researching and developing the rest of the chip ecosystem and how it is all connected. On a call with Intel's process and product team, the company confirmed a few details about how Intel is pushing the boundaries of new technologies with its upcoming high profile graphics products.
An Insight into Intel's Strategy on Chiplets and Packaging
In a call with Intel last week, we spoke with Ramune Nagisetty, the Director of Intel’s Process and Product Integration, to discuss Intel’s strategy with regard to chiplets and packaging technologies. Ramune has spent over twenty years at Intel, working in areas such as transistor definition for 65nm, Intel Labs for technical strategy and wearables, and most recently as heading up Intel’s chiplet strategy for product integration. Ramune focuses on the art of the chiplet or the packaging in its own right, rather than the specific technologies it goes into, and it was an enlighting discussion.

Ramune Nagisetty
The story around chiplets is going to be a cornerstone of the semiconductor market for the next generation, being able to provide smaller silicon for specific tasks and connecting them together. Chiplets form the basis of Intel’s current Stratix 10 FPGA product line, and the future of Intel Agilex, as well as consumer products like Kaby Lake G with its HBM chiplet for fast high-speed memory. How Intel integrates its own chiplets, with the company confirming it is working on migrating its AI portfolio into chiplet form factors, as well as other third party IP, is going to be an important strategy going forward. The art of connecting chiplets, however, is all in the packaging. Intel has several technologies of its own that it uses.
EMIB, Foveros, Interposers: Connect the Data
Intel’s Embedded Die Interconnect Bridge ‘EMIB’ has been a talking point for a couple of years now. Because certain high-performance chiplet designs require high-bandwidth links with many more traces than traditional organic chip packaging can support, there is a need for more exotic means to build these dense connections. The 'brute force' solution here is a silicon interposer, essentially stacking chips on top of a large, 'dumb' silicon die that's in place solely for routing purposes.
With EMIB however, rather than using a full silicon interposer, Intel equips a substrate with just a small embedded silicon connection, allowing a host chip and a secondary chiplet to connect together with high bandwidth and small distances. This technology is currently in Intel’s FPGAs, connecting the FPGA to memory or transceivers or third-party IP, or in Kaby Lake-G, connecting the Radeon GPU to on-package high bandwidth memory.
Intel has also uses full interposers in its FPGA products, using it as an easier and quicker way to connect its large FPGA dies to high bandwidth memory. Intel has stated that while large interposers are a catch-all situation, the company believes that EMIB designs are a lot cheaper than large interposers, and provide better signal integrity to allow for higher bandwidth. In discussions with Intel, it was stated that large interposers likely work best for powerful chips that could take advantage of active networking, however HBM is overkill on an interposer, and best used via EMIB.
Akin to an interposer-like technology, Foveros is a silicon stacking technique that allows different chips to be connected by TSVs (through silicon vias, a via being a vertical chip-to-chip connection), such that Intel can manufacture the IO, the cores, and the onboard LLC/DRAM as separate dies and connect them together. In this instance, Intel considers the IO die, the die at the bottom of the stack, as a sort of ‘active interposer’, that can deal with routing data between the dies on top. Ultimately the big challenges with a multi-die strategy come with in thermal constraints of the dies used (so far, Intel has demonstrated a 1+4 core solution in a 12x12mm package, called Lakefield), as well as aligning known good die for TSV connections.
Discussing Strategy: Intel's Engineering Approach
Intel is clearly committed to its chiplet strategy where it currently stands with FPGAs, bringing other aspects of Intel’s technology to the platform (such as AI), and developing features such as EMIB into it. Ramune made it clear that if Intel’s customers have their own third party IP in use with the FPGA, they will need to either provide the EMIB capable chiplets themselves or work with Intel’s foundry business to enable them, and then the packaging will be done solely at Intel. While Intel has offered connectivity standards to the open market, the specific EMIB technology that Intel uses is designated a product differentiation, so customers will have to engage with Intel in order to see their IP in the packaged product.
![]()
When it comes to chip stacking technologies like Foveros, Ramune reiterated some of the key areas of the technology that are being worked on, such as thermal limitations as well as die size and efficient stacking. One of the key changes was described as ensuring that when dies are stacked that known good dies (i.e. those that pass yield tests) are used, which requires bare die testing before assembly. Some of Intel’s previous development processes have needed to be adjusted in order to assist for technologies like Foveros and products like Lakefield, as well as other products in the future. Ramune did state that Intel has not specifically looked into advanced cooling methods for Foveros type chips, but did expect work in this field over the coming years, either internally or externally.
When discussing products in the future, one critical comment did arise from our conversation. This might have been something we missed back at Intel’s Architecture Day in December last year, but it was reiterated that Intel will be bringing both EMIB and Foveros into its designs for future graphics technologies. As one might imagine, no further comment was offered regarding the scale, thermal performance, interconnect integration, or anything along those lines, but it is clear that Intel is looking into multi-die graphics technologies. One might by cynical and state that Intel is already using both EMIB and Foveros in graphics today: Kaby G uses EMIB, and Lakefield has an integrated Gen11 graphics on Foveros. However these are two separate products, and our takeaway from the conversation was that both of these technologies might be on a singular product in the future.

This could take many different forms. A central control chip connected by EMIB to compute chips, using Foveros to increase the amount of onboard cache each of the control chips has. Compute chips could be daisy chained by EMIB. The control chip could need a central DRAM repository, either by Foveros or via EMIB. These technologies are like Lego – go build a spaceship, or a ferris wheel, or a GPU.
Splitting GPUs into chiplets isn’t a new idea in the realm of ideas, however it is a concept that is difficult to conceive. One of the key areas of shuffling data around a GPU is bandwidth – the other is latency. In a graphics scenario, the race is on to get a low frame rendering time, preferably below 16.67 milliseconds, which allows for a refresh rate of 60 Hz to have a full display frame inserted on every refresh cycle. With the advent of variable refresh displays this has somewhat changed, however the main market for graphics cards, gamers, is heavily reliant on quick refresh rates and high frame rates from their graphics. With a multi-chip module, the manufacturer has to consider how many hops between dies the data has to perform from start to finish – is the data required found directly connected to the compute chip, or does it have to cross from the other side of the design? Is the memory directly stacked, or is there an intrapackage connection? With different memory domains, can the data retain its concurrency through the mathematical operations? Is there a central management die, or do each of the compute chiplets manage their own timing schema? How much of the per-chiplet design comes from connectivity units compared to compute units?
Ultimately this sort of design will only win out if it can compete on at least two fronts of the triad of performance, cost, or power. We already know that multi-die environments typically require a higher power budget than a monolithic design due to the extra connectivity, as seen with multi-die CPU options in the market, so the chiplets will have to take advantage of smaller process nodes in order to eliminate that deficit. Luckily, small chiplets are easier to manufacturer on small process nodes, making it a potential cost saving over big monolithic designs. Performance will depend on the architecture, both for raw compute, as well as the interconnect between the chips.
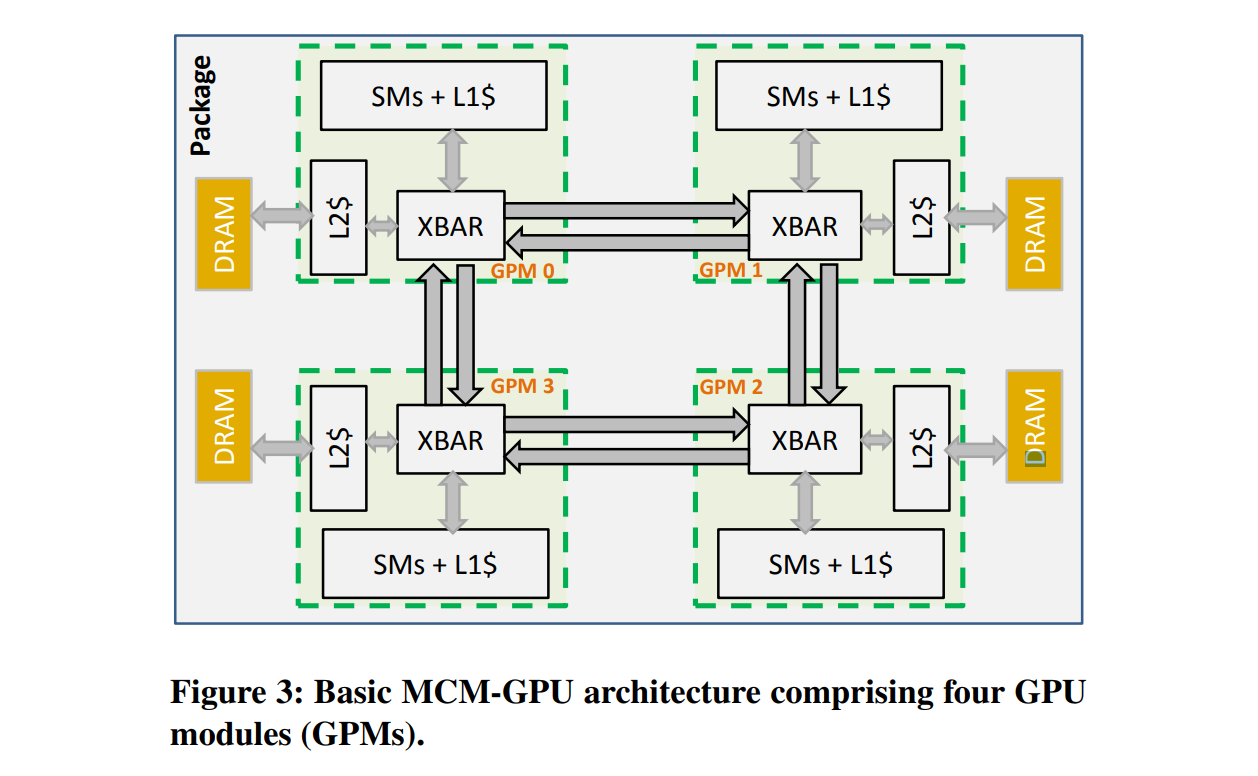
NVIDIA MCM GPU Diagram from ISC '17
We have seen several research papers discuss the concept of a multi-die graphics solution, such as this one from NVIDIA, and you can bet your bottom dollar that everyone involved in high performance graphics and high performance compute is looking at it. Given the fact that a compute platform has fewer restrictions than a graphics platform, we might expect to see a multi-die solution there first.
The other element to our discussion was a reaffirmation of comments made previously by Dr. Murthy Renduchintala, Intel’s Chief Engineering Officer and Group President of the Technology, Systems, Architecture and Client Group. Ramune stated that chiplet technology and packaging technologies are designed to run asynchronously to Intel’s current manufacturing processes. Ultimately the goal here is to apply the technologies to the process currently available, rather than fixing development and tying development to a single node strategy. As we’ve seen with how Intel’s 10nm development has progressed, this disaggregation of product and technology is going to be an important step in Intel’s future.
What We Do Know About Intel's Xe GPU Line
Intel has already stated that after Gen11 graphics, which will be featured in its future Ice Lake consumer processors paired with the Sunny Cove microarchitecture, that we will see its Xe graphics products come to the market. Xe will range from integrated graphics all the way up to enterprise compute acceleration, covering through the consumer graphics and gaming markets as well.
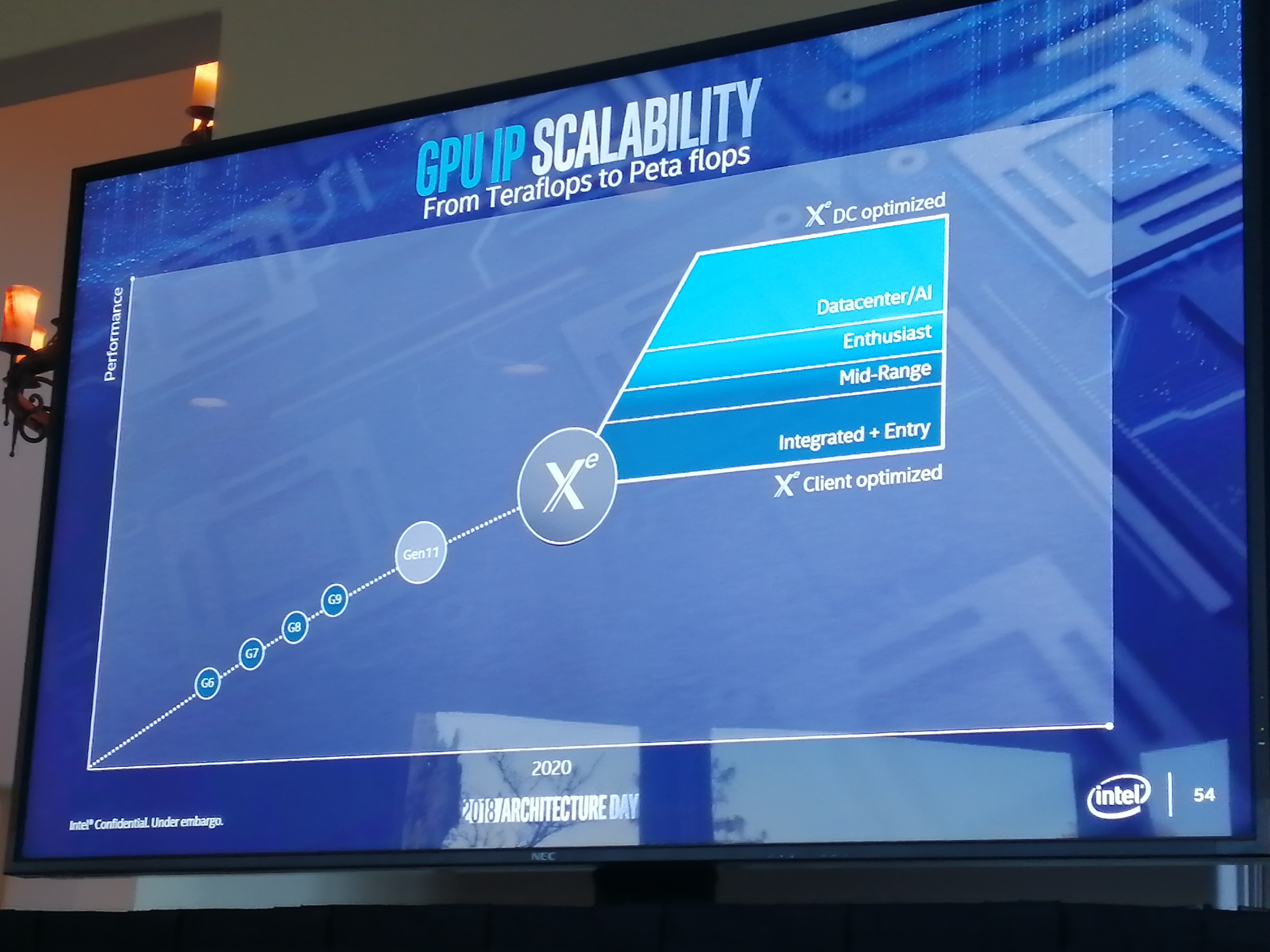
Intel stated at the time that the Xe range will be built on two different architectures, one of which is called Arctic Sound, and the other has not yet been made public. The goal is to create a platform for Xe relating the hardware, the software, the drivers, the platform, and the APIs all into a single mission, which Intel calls 'The Odyssey'. Introducing EMIB and Foveros technologies as part of the Xe strategy seems to be very much part of Intel's plan, and it will be interesting to see how it develops.
Beyond Intel's Core Technologies
Intel’s recent push into graphics technology is well known. The company has hired Raja Koduri from AMD, Jim Keller from Tesla, Chris Hook from AMD, and a number of high profile tech journalists and AMD’s GPU marketing manager to help develop its discrete graphics offerings. Even as of a couple of days ago the company wasn't quite done with their hiring spree, picking up GlobalFoundries' Corporate Communications director to assist in its manufacturing process and packaging technologies disclosures. While 10nm is being fixed, the company is clearly trying to get the attention onto its new product areas, and its new capabilities – we’ve seen new packaging technologies and core configurations at Intel’s Tech Summit in December, and an array of enterprise products other than CPUs at the company’s recent Data Centric launch event. As Intel develops both its chiplet strategy and its packaging implementations, we should expect the expertise to permiate through Intel's product portfolio where it expects to help those products gain an advantage. Lakefield is a key example of this, offering Core, Atom, and Gen11 functionality in a tiny chip and under 7W for small form factor devices.

Lakefield, built with Foveros
Many thanks to Ramune Nagisetty and her team for the call last week, and some insight into a part of Intel we’ve not normally had contact with before. I’m glad that Intel is starting to open up more into new areas like this, and hope that it continues in the future.
Related Reading
- Hot Chips: Intel EMIB and 14nm Stratix 10 FPGA
- Intel Launches Stratix 10 TX: Leveraging EMIB with 58G Transceivers
- Intel Agilex: 10nm FPGAs with PCIe 5.0, DDR5, and CXL
- Intel's Architecture Day 2018: The Future of Core, Intel GPUs, 10nm, and Hybrid x86
- CES 2019 Quick Bytes: Intel’s 10nm Hybrid x86 Foveros Chip is Called Lakefield
- Intel’s Keynote at CES 2019: 10nm, Ice Lake, Lakefield, Snow Ridge, Cascade Lake
- Intel’s Enterprise Extravaganza 2019: Launching Cascade Lake, Optane DCPMM, Agilex FPGAs, 100G Ethernet, and Xeon D-1600
- Intel to Create new 8th Generation CPUs with AMD Radeon Graphics with HBM2 using EMIB








117 Comments
View All Comments
FireSnake - Wednesday, April 17, 2019 - link
So they will follow path of AMD - with chiplets. Nice :)Targon - Wednesday, April 17, 2019 - link
There hasn't been a lot of talk about when this will apply to Intel consumer parts, other than CPU+GPU in one package. AMD clearly spent a fair amount of time paying attention to the whole idea of how different components within a computer can talk to each other to better streamline the overall computer. As a result, we saw AMD linking Infinity Fabric to memory speed, and the hope is that with third generation Ryzen chips, we will see this go away and just run IF at a high speed, no matter what RAM is used in the system. That would then beg the question if that advancement would apply only to systems with a 500 series chipset, or if the 300 and 400 series chipsets would also benefit from that change.HStewart - Wednesday, April 17, 2019 - link
I don't believe this is following AMD path at all and AMD did not event MCM technology. People like to give AMD more credit than they deserved.I more curious about connection between EMiB and Foveros. The diagram with Package Technology Roadmap shows that Foveros is next evolution or possibly revolution of EMiB. But the AgileX diagram looks like EMiB is a connector.
It could be the Foveros is use stacking layers and using EMiB connect components. So Kaby G is just a single layer of Foveros. I think something important is really over look with importance of Kaby G with EMiB - this is important because it links different manufacture process even from different vendors ( Intel and AMD ) and it is important test ground for future Intel Plans.
Personally I think is crazy that we have super huge chips in todays world and going to 3D on chips is next revolution on packaging technology. I also see one day AMD licensing Foveros or duplicating their own version to reduce the size of there chips.
AshlayW - Wednesday, April 17, 2019 - link
Maybe not following AMD directly, but AMD is sure ahead of the game, with MCM CPU's shipping for over a year now. Intel was quick to point out the flaws in MCM; but now they are gonna do it too. AMD paving the way as usual :)HStewart - Wednesday, April 17, 2019 - link
I with EMiB in Kaby G, I would say that Intel is ahead of the game. Can AMD connect on same chip non AMD excluding Intel Kaby G Processor like in last years Dell XPS 15 2in1.One Intel Chip that currently uses this technology is Kaby G processor that was release Q1 of 2018.
But lets stop looking at the past, this is about the future and everything is likely going to EMiB / Foveros in Intel's future include new graphics chips.
It would be interesting to see what next generation Dell XPS 15 2in1 is? My guess it will Intel CPU with Gen 11 Graphics. Performance wise I expect it to beat Kaby G in graphics area.
darkswordsman17 - Wednesday, April 17, 2019 - link
AMD does have experience with interposers with HBM, which yes is different from EMIB but when it comes down to it, they both have experience placing chips embedded on the same board (which is what they're doing with these other technologies, just in different manners). AMD has experience integrating other companies' IP into their chip as well. It really just comes down to syncing the necessary communication bits so the chips can properly talk to each other (not to make light of that, its actually a pretty difficult issue to get sorted out at transistor level). Which I think is the main driver behind AMD going to a separate I/O chip, it lets them customize that for different customers and as the need fits, while being able to maximize economies of scale of their base CPU/GPU components.I think we're seeing both just starting on the transition to chiplet designs, so its hard to say where things will go from here. Which, even just for their own short term future we have a lot to see on what they can offer (CPU and GPU performance for instance).
FreckledTrout - Monday, April 22, 2019 - link
I agree. AMD is taking an incremental approach and Intel is going more revolutionary with EMIB. I think both camps will end up at pretty much the same destination by 2022. I tend to think strategically AMD made the better decisions. Take Intel's 10nm where they were pushing the densities and it bit them hard. This is why it was mentioned Intel is designing for the process they have.HStewart - Monday, April 22, 2019 - link
We would just have to agree to disagree with this - but I not sure they are heading in same direction - AMD is getting bigger and Intel is getting smaller especially with Fovores. But Intel has learn from it mistakes with 10 nm and coming back hard with new Favs and Sunny Cove architexture. Just remember that nm number does not matter what matter is how much technology can be put in same space and how fast.Korguz - Monday, April 22, 2019 - link
" But Intel has learn from it mistakes with 10 nm and coming back hard with new Favs and Sunny Cove architexture. ( architecture ) " yea right.. unless you are able to see into the future HStewart, this is a false statement... until intel proves it... face it.. just like with the Athon64, intel was caught with its pants down... the sleeping giant, as you once put it.. finally woken up.. and is now playing catch up.once again.. some one puts amd up.. and you come along.. put them down.. but try to prop intel up...
Haawser - Wednesday, April 17, 2019 - link
Intel didn't invent EMIB either. They license it afaia- https://patents.google.com/patent/US20180108612A1/... Not sure if it's an exclusive license though.