Intel’s 14nm Technology in Detail
by Ryan Smith on August 11, 2014 12:45 PM EST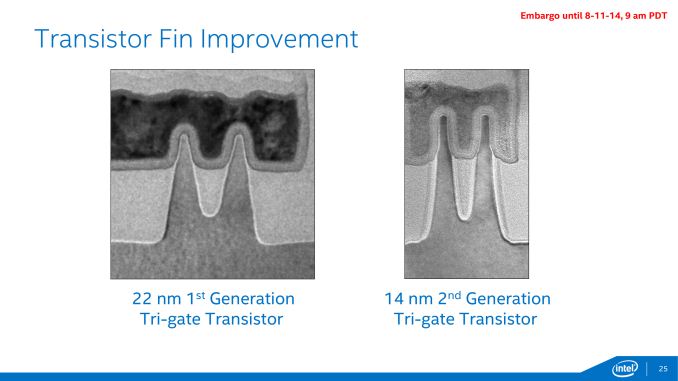
Much has been made about Intel’s 14nm process over the past year, and admittedly that is as much as Intel’s doing as it is the public’s. As one of the last Integrated Device Manufacturers and the leading semiconductor manufacturer in the world, Intel has and continues to set the pace for the semiconductor industry. Which means that Intel’s efforts to break the laws of physics roughly every 2 years mark an important milestone in the continuing development of semiconductor technology and offer a roadmap of sorts to what other semiconductor manufacturers might expect.
To that end, at a time when ramping up new process nodes is more complex and more expensive than ever, Intel’s 14nm process is especially important. Although concerns over the immediate end of Moore’s Law remain overblown and sensationalistic, there is no denying that continuing the pace of Moore’s Law has only gotten more difficult. And as the company on the forefront of semiconductor fabrication, if anyone is going to see diminishing returns on Moore’s Law first it’s going to be Intel.
Today Intel is looking to put those concerns at rest. Coinciding with today’s embargo on Intel’s 14nm technology and a preview of Intel’s upcoming Broadwell architecture based Core M processor, Intel will be holding a presentation dubbed Advancing Moore’s Law in 2014. Intel for their part is nothing short of extremely proud over what advancements they have made over the last several years to make their 14nm process a reality, and with that process now in volume production in their 14nm Oregon fab and being replicated to others around the world, Intel is finally ready to share more information about the 14nm process.
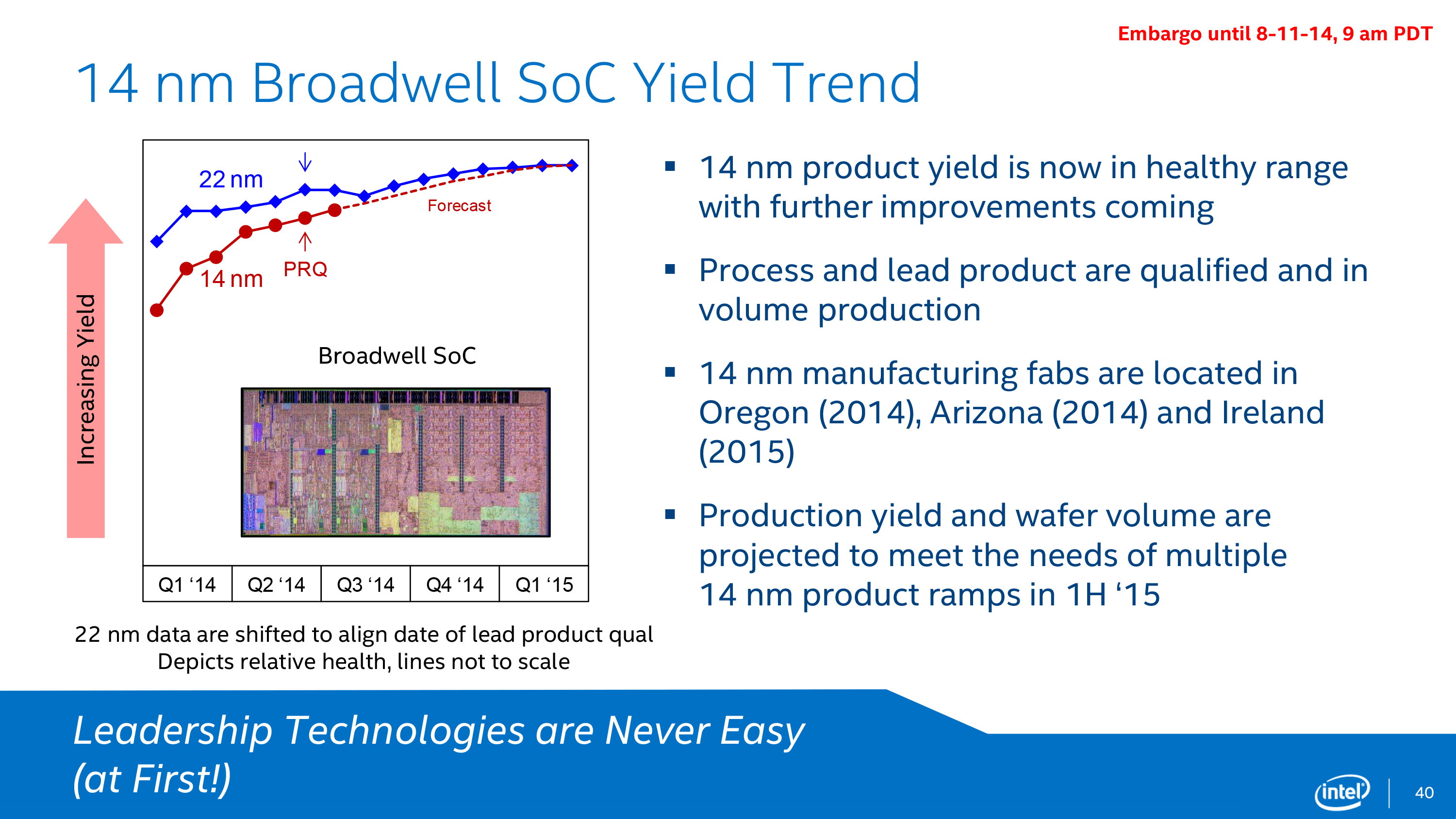
We’ll start off our look at Intel’s 14nm process with a look at Intel’s yields. Yields are important for any number of reasons, and in the case of Intel’s 14nm process the yields tell a story of their own.
Intel’s 14nm process has been their most difficult process to develop yet, a fact that Intel is being very straightforward about. Throughout the life of the 14nm process so far its yields have trailed the 22nm at equivalent points in time, and while yields are now healthy enough for volume production Intel still has further work to do to improve the process to catch up with 22nm. In fact at the present Intel’s 22nm process is the company’s highest yielding (lowest defect density) process ever, which goes to show just how big a set of shoes the up and coming 14nm process needs to fill to completely match its predecessor.
Concerns over these yields has no doubt played a part in Intel’s decision to go ahead with today’s presentation, for if nothing else they need to showcase their progress to their investors and justify the company’s heavy investment into 14nm and other R&D projects. While 14nm has made it into production in 2014 and the first 14nm products will hit retail by the end of the year, these yield issues have caused 14nm to be late for Intel. Intel’s original plans, which would have seen the bulk of their Broadwell lineup launch in 2014, have been reduced to the single Broadwell-Y SKU this year, with the rest of the Broadwell lineup launching in 2015.
Ultimately while 14nm is still catching up to 22nm, Intel is increasingly confident that they will be able to finish catching up, forecasting that 14nm will reach parity with 22nm on a time adjusted basis in the first quarter of 2015, or roughly 6 months from now. Intel is already in the process of replicating their 14nm to their other fabs, with fabs in Arizona and Ireland expected to come online later this year and in 2015 respectively. These fab ramp-ups will in turn allow Intel to further increase their manufacturing capacity, with Intel projecting that they will have sufficient volume to handle multiple 14nm product ramps in H1’2015.
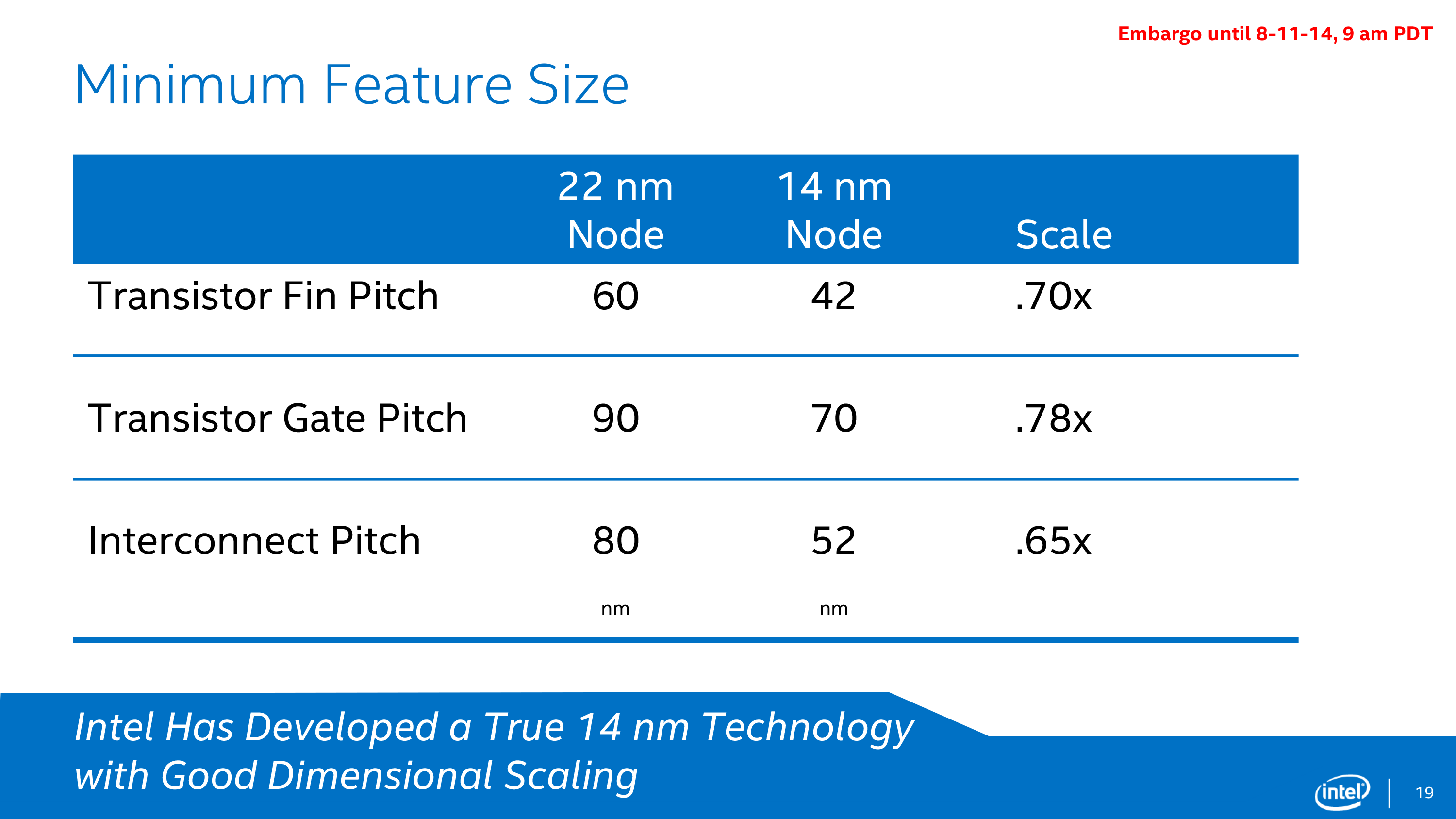
Moving on to the specifications and capabilities of their 14nm process, Intel has provided the minimum feature size data for 3 critical feature size measurements: transistor fin pitch, transistor gate pitch, and the interconnect pitch. From 22nm to 14nm these features have been reduced in size by between 22% and 35%, which is consistent with the (very roughly) 30%-35% reduction in feature size that one would expect from a full node shrink.
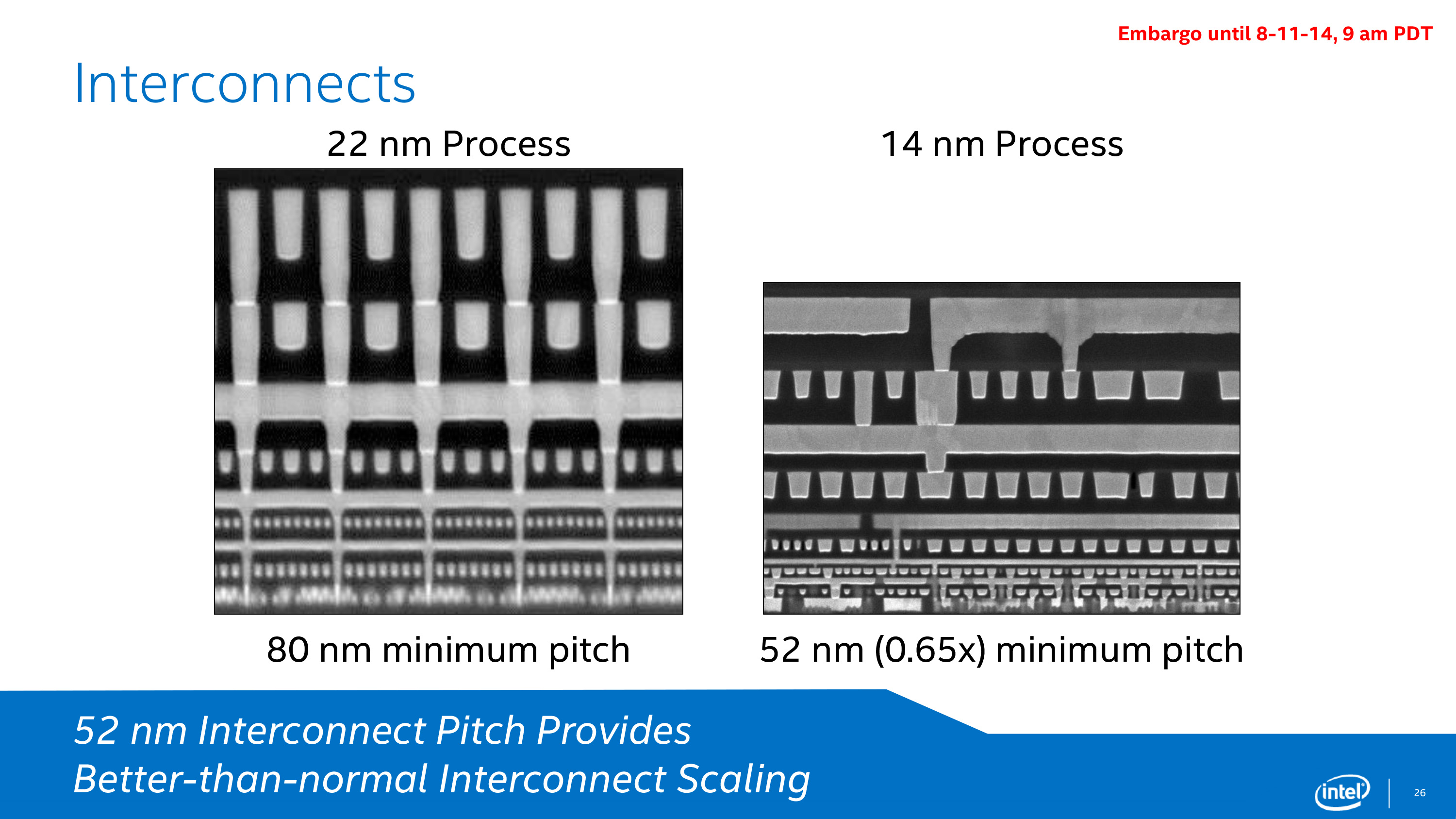
Intel is especially proud of their interconnect scaling on the 14nm node, as the 35% reduction in the minimum interconnect pitch is better than normal for a new process node.
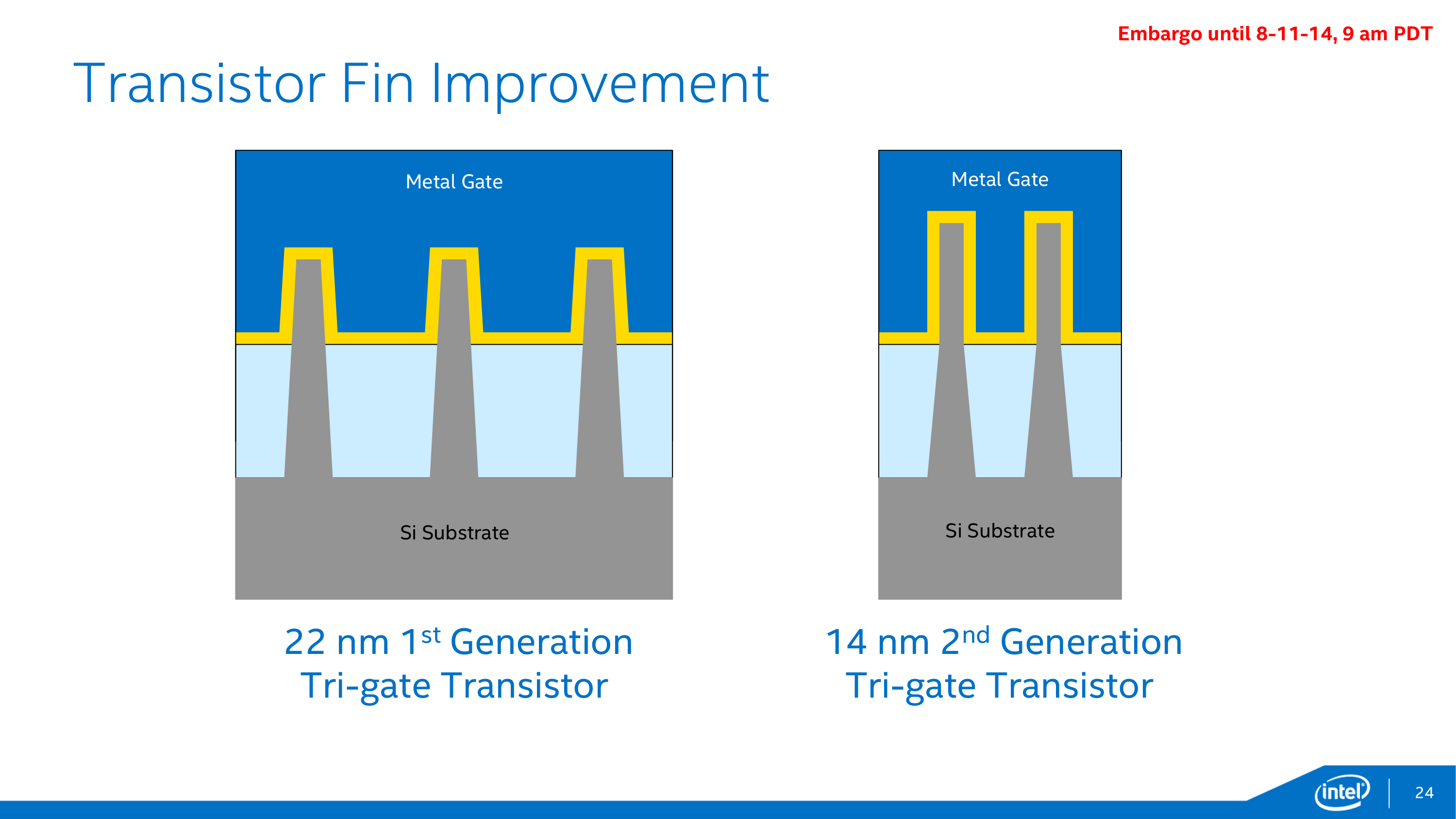
Along with the immediate feature size improvements that come with a smaller manufacturing node, Intel has also been iterating on their FinFET technology, which is now in its second generation for the 14nm process. Compared to the 22nm process, the 14nm process’s fins are more tightly packed, thinner, taller, and fewer in number (per transistor).
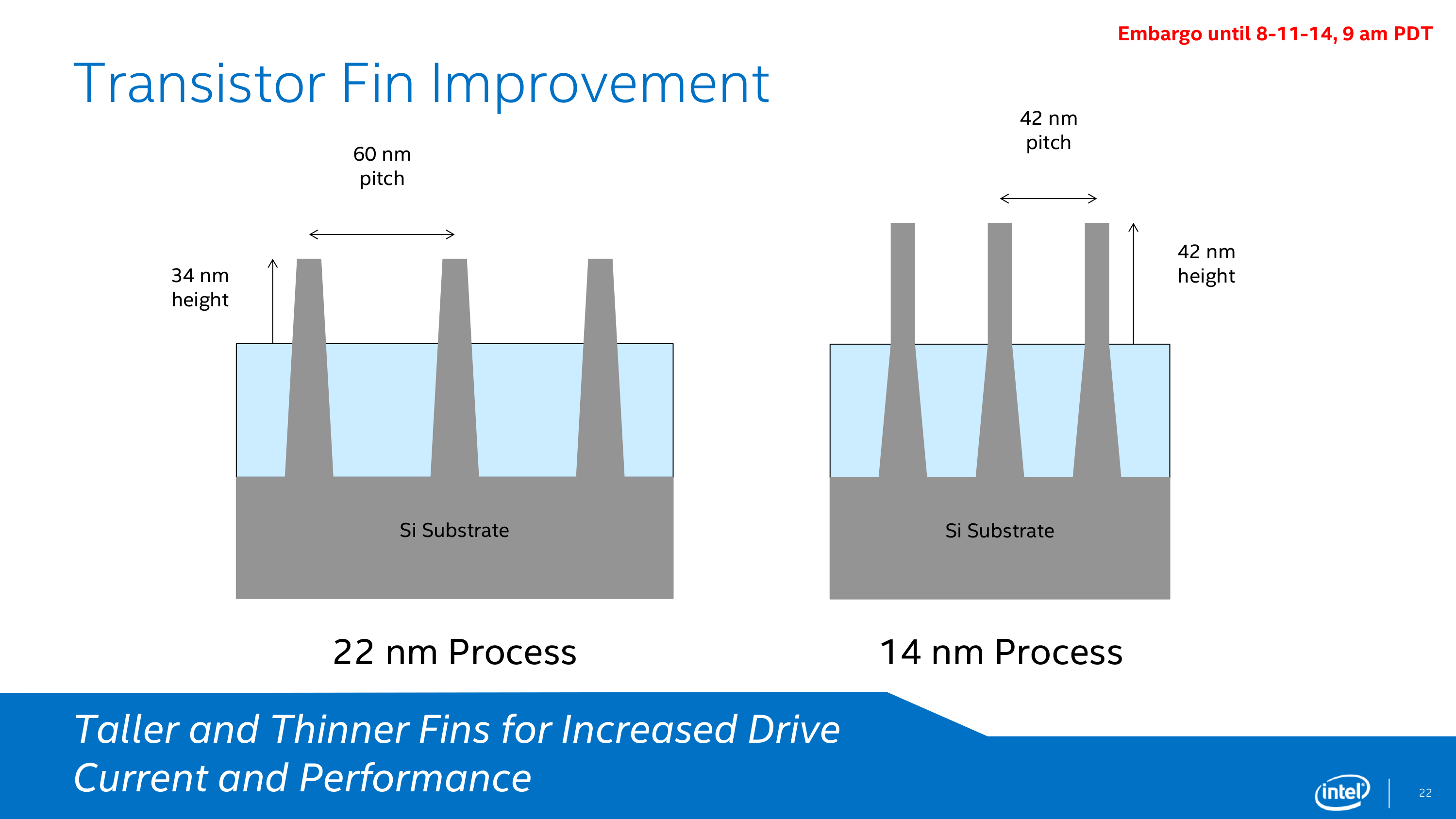
Each one of these changes in turn improves the performance of the FinFETs in some way. The tighter density goes hand-in-hand with 14nm’s feature size reductions, while the taller, thinner fins allow for increased drive current and increased performance. Meanwhile by reducing the number of fins per transistor, Intel is able to improve on density once again while also reducing the transistor capacitance that results from those fins.


Intel is also reporting that they have been able to maintain their desired pace at improving transistor switching speeds and reducing power leakage. Across the entire performance curve the 14nm process offers a continuum of better switching speeds and/or lower leakage compared to Intel’s 22nm process, which is especially important for Intel’s low power ambitions with the forthcoming Core M processor.
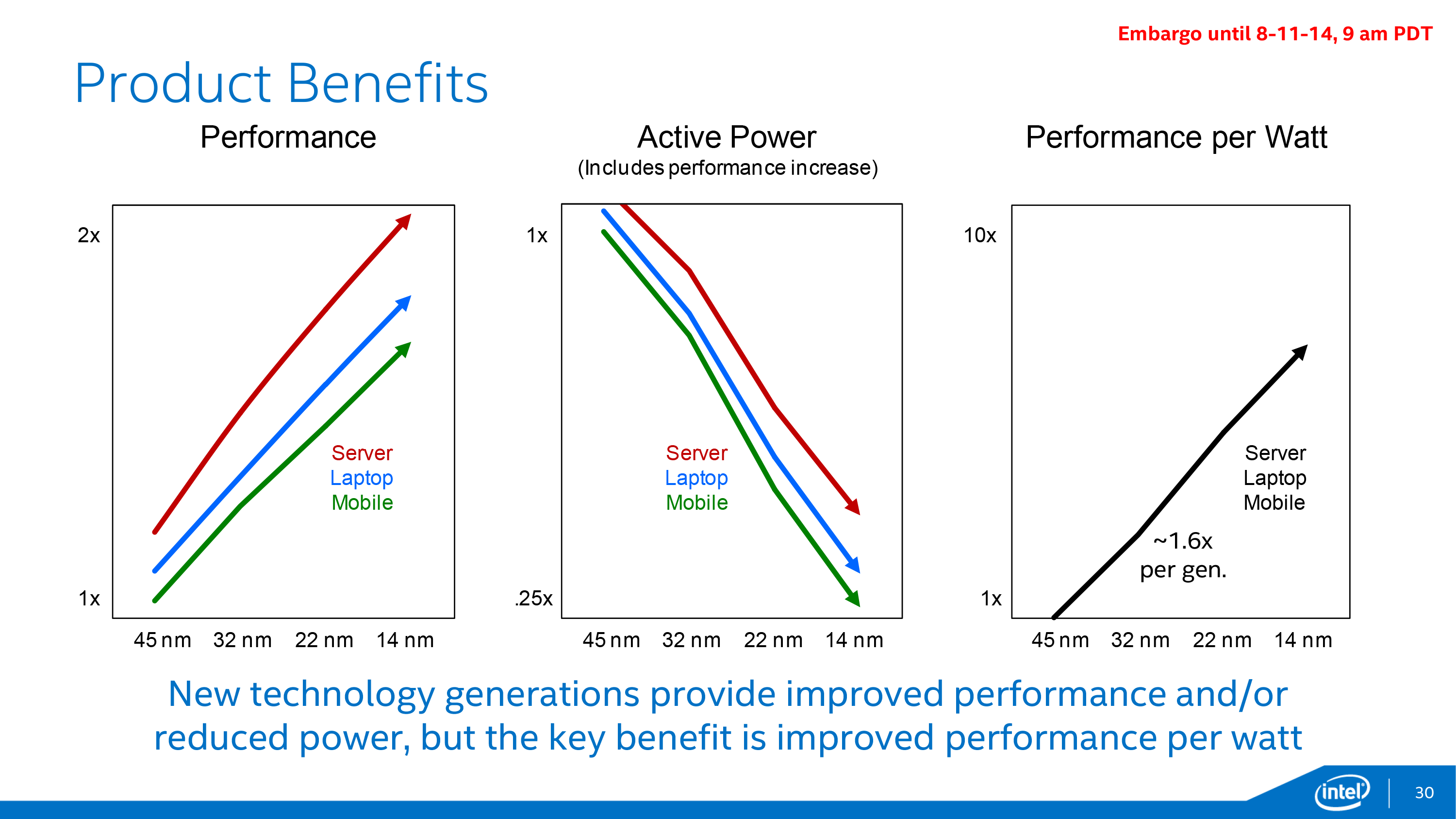
Plotted differently, here we can see how the last several generations of Intel’s process nodes compare across mobile, laptop, and server performance profiles. All 3 profiles are seeing a roughly linear increase in performance and decrease in active power consumption, which indicates that Intel’s 14nm process is behaving as expected and is offering similar gains as past processes. In this case the 14nm process should deliver a roughly 1.6x increase in performance per watt, just as past processes have too.
Furthermore, these base benefits when coupled with Intel’s customized 14nm process for Core M (Broadwell-Y) and Broadwell’s power optimizations have allowed Intel to more than double their performance per watt as compared to Haswell-Y.
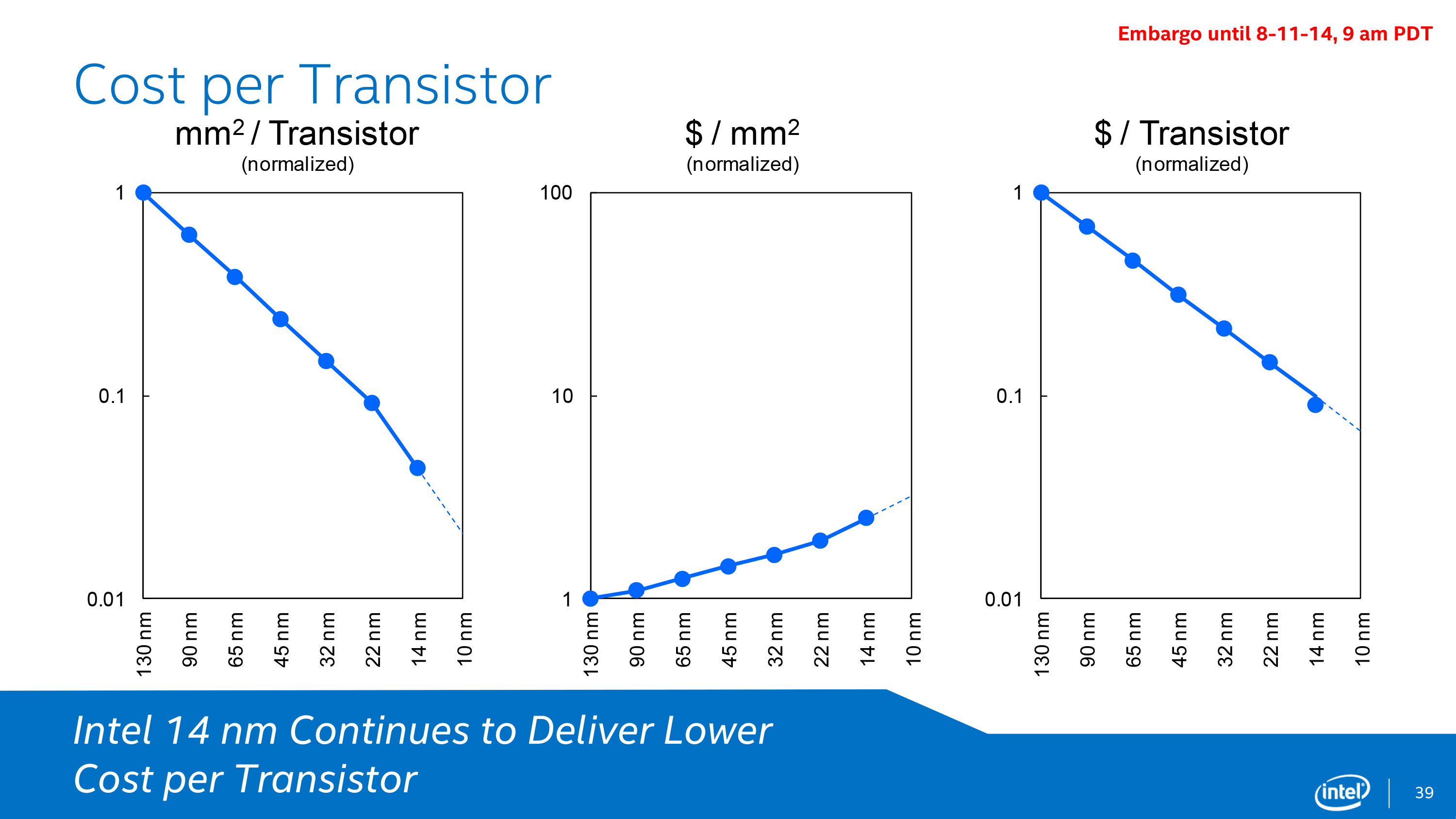
Moving on to costs, Intel offers a breakdown of costs on a cost per mm2 and pairs that with a plot of transistor sizes. By using more advanced double patterning on their 14nm node Intel was able to achieve better than normal area scaling, as we can see here. The tradeoff for that is that wafer costs continue to rise from generation to generation, as double patterning requires additional time and ever-finer tools that drive up the cost of production. The end result is that while Intel’s cost per transistor is not decreasing as quickly as the area per transistor, the cost is still decreasing and significantly so. Even with the additional wafer costs of the 14nm process, on a cost per transistor basis the 14nm process is still slightly ahead of normal for Intel.
At the same time the fact that costs per transistor continue to come down at a steady rate may be par for the course, but that Intel has been able to even maintain par for the course is actually a very significant accomplishment. As the cost of wafers and fabbing have risen over the years there has been concern that transistor costs would plateau, which would lead to chip designers being able to increase their performance but only by increasing prices, as opposed to the past 40 years of cheaper transistors allowing prices to hold steady while performance has increased. So for Intel this is a major point of pride, especially in light of complaints from NVIDIA and others in recent years that their costs on new nodes aren’t scaling nearly as well as they would like.
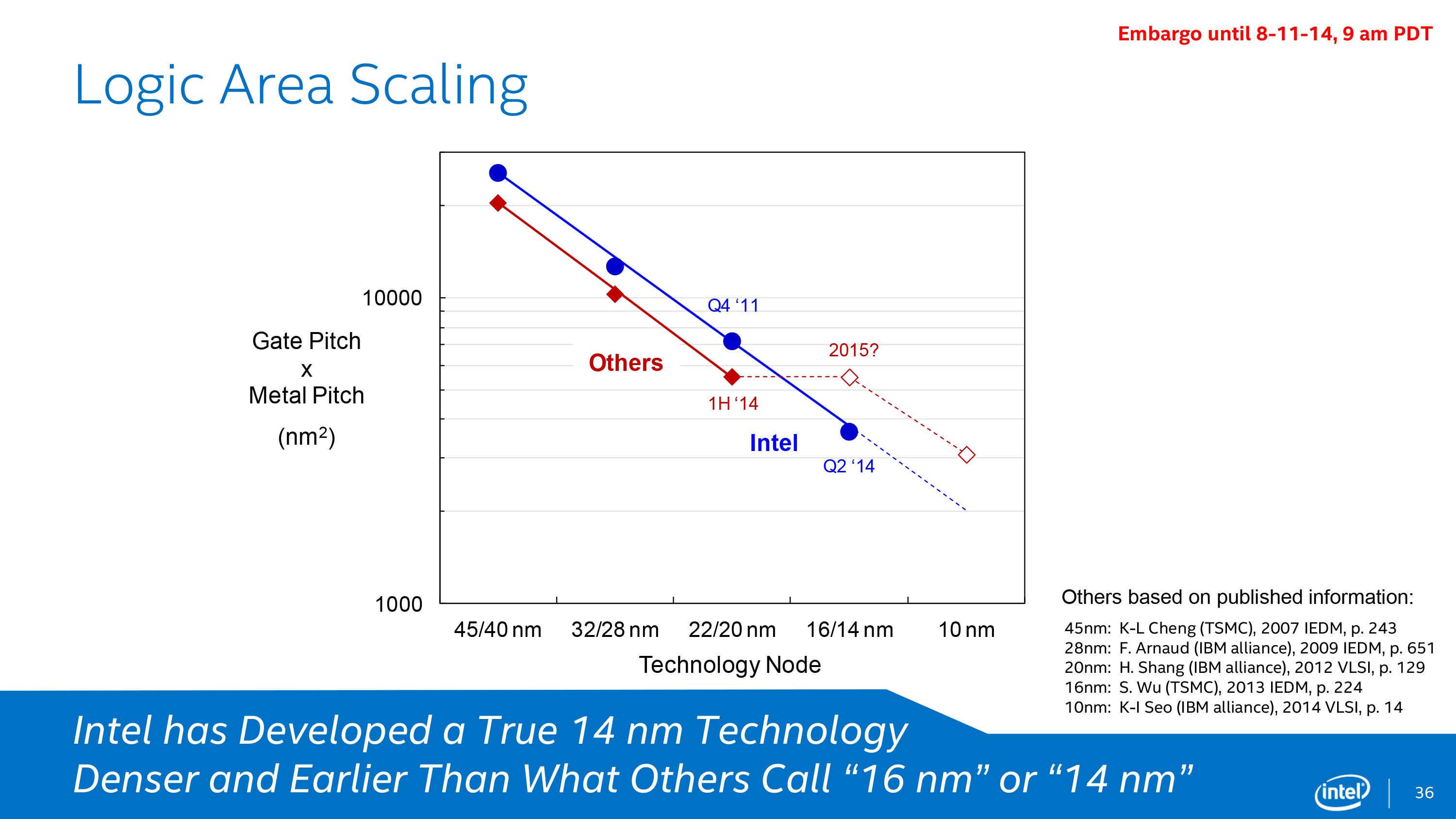
Which brings us to the final subject of Intel’s 14nm presentation, the competitive landscape. Between the ill-defined naming of new process nodes across the entire industry and Intel’s continuing lead in semiconductor manufacturing, Intel likes to point out how their manufacturing nodes compare to foundry competitors such as TSMC and the IBM alliance. Citing 3rd party journal articles for comparison, Intel claims that along with their typical lead in rolling out new nodes, as of the 14nm node they are going to have a multiple generation technical advantage. They expect that their 14nm node will offer significantly smaller feature sizes than competing 14nm nodes, allowing them to maintain consistent logic area scaling at a time when their competitors (i.e. TSMC) cannot.
From a technical perspective it's quite obvious why it is that Intel is able to maintain density scaling above the level that TSMC and Common Platform members can deliver. In short, this goes back to the improved interconnect density that was discussed earlier in this article. While Intel is pushing 14nm transistor and interconnect, TSMC and Common Platform members are using the same interconnect technology that they did at 20nm. This means that only areas where transistor density was the gating factor for 20nm will decrease in size at 14/16nm, while areas already gated by 20nm interconnect technology won't be able to get any smaller.
Thus for what it’s worth the basic facts do appear to check out, but we would be the first to point out that there is more to semiconductor manufacturing than just logic area scaling. At least until Intel’s competitors start shipping their FinFET products this is going to be speculative, and doesn’t quantify how well those competing process nodes will perform. But then again, the fact that Intel is already on their second FinFET node when their competitors are still ramping up their first is no small feat.

Wrapping things up, while Intel’s bring up of their 14nm process has not been without problems and delays, at this point Intel appears to be back on track. 14nm is in volume production in time for Broadwell-Y to reach retail before the end of the year, and Intel is far enough along that they can begin replicating the process to additional fabs for production in 2014 and 2015. Meanwhile it will still be a few months before we can test the first 14nm chips, but based on Intel’s data it looks like they have good reason to be optimistic about their process. The feature size and leakage improvements are in-line with previous genartion process nodes, which should be a great help for Intel in their quest to crack the high performance mobile market in the coming year.








38 Comments
View All Comments
R3dox - Tuesday, August 12, 2014 - link
While I appreciate the technical info, I'm a bit surprised to see this being called exclusively Intel's. Afaik, the main struggle here was ASML's, making the machines used to make the chips. From what I heard, ASML works quite closely (considering the IP they see of all of them) with chipmakers to build these machines for the process they need.kuroxp - Tuesday, August 12, 2014 - link
Do you work for ASML? :D What about TEL? AMAT? NIKON? any other big names in equipment manufacturing? Not to mention materials - photoresist, gas, chemical, list goes on. Maybe we can have one big party. :)R3dox - Wednesday, August 13, 2014 - link
No :p. But from what I understood they are marketleader (by a pretty large margin) and specifically working together with intel to get 14nm working as it was quite problematic. Maybe I'm wrong, I'm not in that industry ;).daScribe - Monday, August 25, 2014 - link
There are at least 20 different major equipment manufacturers who work hard to meet the specs for the next generation tools as required by Intel. Once they deliver, the battle actually begins to get the design done (things don't just get drawn as is from previous generation with a reduced size), the masks made and the whole process for the silicon to work out. Every single cog in the huge machinery of Intel and its OEMs has to fire just right to make these chips work. I hope you get a sense from this as to how difficult and amazing a feat it is for Intel to produce these chips with high yield.markbanang - Friday, August 15, 2014 - link
I worked for a company which produced one of the first EUV lithography tools, and worked on the first EUV actinic imaging mask defect inspection tool, and can tell you that there is very close cooperation between semiconductor manufacturers and their machine suppliers.Although we had to do a lot of original research to overcome the engineering challenges of the brief from Intel/Sematech, only once the machines fulfil the spec and are handed over does the *real* research start. Process window optimisation is the real challenge here. It's one thing to lay down 14nm features, but getting from mask set to processor is an entirely different level level of challenge.
markbanang - Friday, August 15, 2014 - link
I would love to know details of the technology used to produce silicon at the 14nm node.The wikipedia pages on EUV Lithography and Immersion Lithography suggests that these chips might be being produced using double or triple patterning with 193nm immersion lithography. If that's the case, then it it truly remarkable 193nm light can be used to print features this small, when you would expect this to be way beyond the diffraction limit of such a system.
c plus plus - Saturday, August 16, 2014 - link
go oh intel! slay all cpu makers except amd cause we need them. but please double single thread performance with broadwellsandeep patil - Thursday, August 28, 2014 - link
Hi Guys,Sorry but couldn't figure what's 14 in 14nm technology.