The Snapdragon 8 Gen 1 Performance Preview: Sizing Up Cortex-X2
by Dr. Ian Cutress on December 14, 2021 8:00 AM ESTMachine Learning: MLPerf and AI Benchmark 4
Even as a new benchmark in the space, MLPerf has been made available that runs representative workloads on devices and takes advantage of both common ML frameworks such as NNAPI as well as the respective chip libraries for each vendor. Using this benchmark on retail phones to date, Qualcomm has had the lead in almost all the tests, but given that the company is promoting a 4x increase in AI performance, it will be interesting to see if that comes across all of MLPerf’s testing scenarios.
It should be noted that Apple’s CoreML is currently not supported, hence the lack of Apple numbers here.




Across the board in these first four tests Qualcomm is making a sizable lead, going above and beyond what the S888 can do. Here we’re seeing up to a 2.2x result, making an average +75% gain. It’s not quite the 4x that Qualcomm promoted in its materials, but there’s a sizable gap with the other high-end silicon we’ve tested to date.
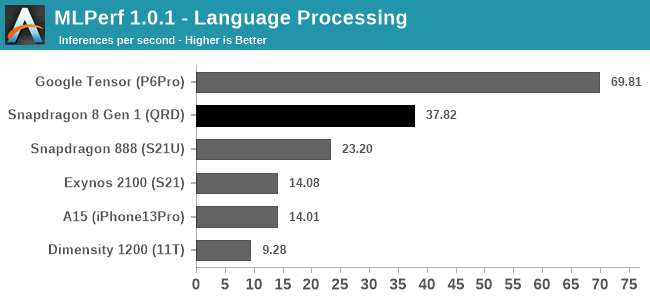
The only non-lead is with the language processing, where Google’s Tensor SoC is almost 2x what the S8g1 scores. This test is based on a mobileBERT model, and either for software or architecture reasons, it fits a lot better into the Google chip than any other. As smartphones increase their ML capabilities, we might see some vendors optimizing for specific workloads over others, like Google has, or offering different accelerator blocks for different models. The ML space is also fast paced, so perhaps optimizing for one type of model might not be a great strategy long-term. We will see.
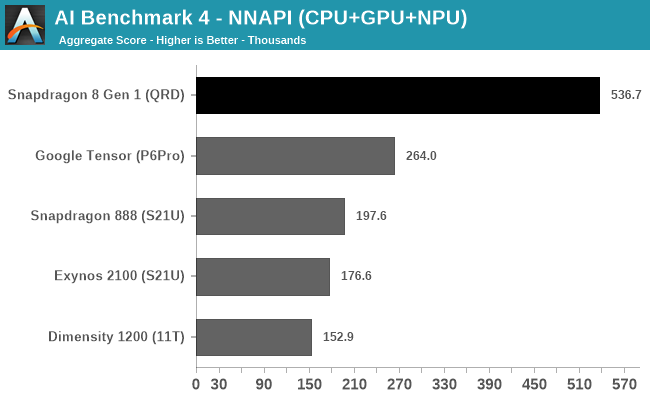
In AI Benchmark 4, running in pure NNAPI mode, the Qualcomm S8g1 takes a comfortable lead. Andrei noted in previous reviews with this test that the power consumed during this test can be quite high, up to 14 W, and this is where some chips might be able to pull ahead an efficiency advantage. Unfortunately we didn’t record power at the same time as the test, but it would be good to monitor this in the future.








169 Comments
View All Comments
eastcoast_pete - Tuesday, December 14, 2021 - link
I guess that's one "impressive" benchmark score, just not the one any user would hope for. Less than 10% complete after half an hour is pretty abysmal. Doesn't bode well for ARM's supposedly much improved LITTLE core designs. Just for comparison, how did the last A55 cores perform in that test?dudedud - Wednesday, December 15, 2021 - link
Andrei said something along the lines of 14hrs for both int and fp SPEC 06.Wilco1 - Thursday, December 16, 2021 - link
Remember the little cores are much slower than the big cores since they have very little cache and run at a low frequency. In SD888 the little cores are 6.4 times slower than the big core. That should be reduced to about 5 times in 8gen1.I think having 4 little cores is too much, they don't contribute to benchmark scores, so you could have just 1 or 2 for background tasks and use the area to quadruple the tiny L2.
iphonebestgamephone - Thursday, December 16, 2021 - link
They do contribute to benchmark scores, 4 of them can be helpful when you need to load up all 4 big cores for the foreground and theres still some background tasks going on.Wilco1 - Saturday, December 18, 2021 - link
That does not make sense. The little cores have almost no L2 cache so will be competing with (and slowing down) the big cores due to the small L3. Having fewer little cores with a much larger L2 means more L3 is available per core, improving performance when all cores are loaded.A little core is most useful for background tasks when the screen is off and mid/big cores are powered down. If you have more background tasks than a single little core could handle, then it's not really "background", and it would be better to run them on a mid core since that will be several times more efficient than 4 little cores (see the efficiency graph, the mid core in eg. SD888 has about the same efficiency as a maxed out little core).
iphonebestgamephone - Sunday, December 19, 2021 - link
When all 3 mid cores and the prime core are fully loaded in apps that use 4 threads, the little cores are doing all the background tasks. How much l3 do background tasks need anyway?syxbit - Tuesday, December 14, 2021 - link
>>There is no AV1 decode engine in this chip, with Qualcomm’s VPs stating that the timing for their IP block did not synchronize with this chip.This is very disappointing. The Radeon 6800, which launched over a year ago has hardware AV1 decode. I imagine the 2021 Exynos and Tensor chips will all do AV1
TheinsanegamerN - Tuesday, December 14, 2021 - link
AV1 wont be necessary for a decade at least. AV1 only hit stable 1.0 spec in 2019, this chip was likely already in the design phase beforehand.movax2 - Wednesday, December 15, 2021 - link
YouTube and Netflix already uses AV1 for a good portion of their videos. Your statement is wrong.GC2:CS - Tuesday, December 14, 2021 - link
The GPU upgrade seems absolutelly massive.I have not seen 50% gain in years if i remember corectly.