Dissecting Intel's EPYC Benchmarks: Performance Through the Lens of Competitive Analysis
by Johan De Gelas & Ian Cutress on November 28, 2017 9:00 AM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Skylake-SP
- Xeon Platinum
- EPYC
- EPYC 7601
Database Performance & Variability
Results are very different with respect to transactional database benchmarks (HammerDB & OLTP). Intel's 8160 has an advantage of 22 to 29%, which is very similar to what we saw in our own independent benchmarking.

One of the main reasons is data locality: data is distributed over the many NUMA nodes causing extra latency for data access. Especially when data is locked, this can cause performance degradation.

Intel measured this with their own Memory Latency Checker (version 3.4), but you do not have rely on Intel alone. AMD reported similar results on the Linley Processor conference, and we saw similar results too.
There is more: Intel's engineers noticed quite a bit of performance variation between different runs.
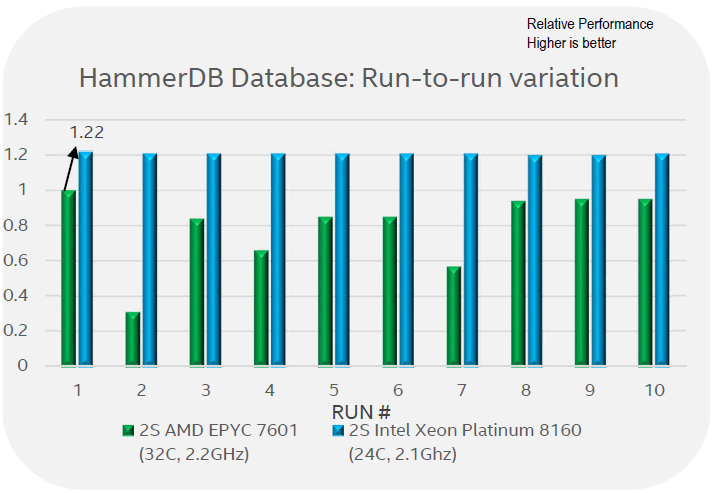
Intel engineers claim that what they reported in the first graph on this page is, in fact, the best of 10 runs. Between the 10 runs, it is claimed there was a lot of variability: ignoring the outlier number 2, there are several occasions where performance was around 60% of the best reported value. Although we can not confirm that the performance of the EPYC system varies precisely that much, we have definitely seen more variation in our EPYC benchmarks than on a comparable Intel system.








105 Comments
View All Comments
lefty2 - Tuesday, November 28, 2017 - link
When Skylake runs AVX 512 and AVX2 instructions it causes both the clock frequency to go down *and* the voltage to go up. (https://www.intel.com/content/dam/www/public/us/en... However, it can only bring the voltage back down within 1ms. If you get a mix of AVX2 and regular instructions, like you do in the POV ray test, then it's going to be running on higher voltage the whole time. That probably explains why the Xeon 8176 drawed so much more power than the EPYC in your Energy consumption test.The guys at cloudflare also observed a similar effect (although they only notice the performance degrade): https://blog.cloudflare.com/on-the-dangers-of-inte...
Kevin G - Tuesday, November 28, 2017 - link
In the HPC section, the article indicates that NAMD is faster on the Epyc system but the accompanying graphic points toward a draw with the Xeon Gold 6148 and a win for the Xeon Platinum 8160. Epyc does win a few benchmarks in the list prior to NAMD though.Frank_han - Tuesday, November 28, 2017 - link
When you run those tests, have you bind CPU threads, how did you take care of different layers of numa domains.UpSpin - Tuesday, November 28, 2017 - link
HIghly questionable article:"A lot of time the software within a system will only vaguely know what system it is being run on, especially if that system is virtualised". Why do you say this if you publish HPC results? There the software knows exactly whay type of processor in what kind of configuration it is running.
"The second is the compiler situation: in each benchmark, Intel used the Intel compiler for Intel CPUs, but compiled the AMD code on GCC, LLVM and the Intel compiler, choosing the best result" More important, what type of math library did they use? The Intel MKL has an unmatched optimization, have they used the same for the AMD system?
"Firstly is that these are single node measurements: One 32-core EPYC vs 20/24-core Intel processors." Why don't you make it clear, that by doing this, the benchmark became useless!!! Performance doesn't scale linearly with core count: http://www.gromacs.org/@api/deki/files/240/=gromac...
So it makes a huge difference if I compare a simulation which runs on 32 cores with a simulation which runs on 20 cores. If I calculate the performance per core then, I always see that the lower core CPU is much much faster, because of scaling issues of the simulation software. You haven't disclosed how Intel got their 'relative performance' value.
Elstar - Tuesday, November 28, 2017 - link
Do we know for sure that the Omni-Path Skylake CPUs actually use PCIe internally for the fabric port? If you look at Intel's "ark" database, all of the "F" parts have one fewer UPI links, which seems weird.HStewart - Tuesday, November 28, 2017 - link
I think this was a realistic article on analysis of the two systems. And it does point to important that Intel system is more mature system than AMD EPYC system. My personally feeling is that AMD is thrown together so that claim core count without realistically thinking about the designed.But it does give Intel a good shot in ARM with completion and I expect Intel's next revision to have significantly leap in technology.
I did like the systems for similarly configured - as the cost, I build myself 10 years a dual Xeon 5160 that was about $8000 - but it was serious machine at the time and significantly faster than normal desktop and last much longer. It was also from Supermicro and find machine - for the longest time it was still faster than a lot machine you can get at BestBuy - it has Windows 10 on it now and still runs today - but I rarely used it because I like the portability of laptops
gescom - Tuesday, November 28, 2017 - link
https://www.servethehome.com/wp-content/uploads/20...And suddenly - 8 core 6134 Skylake-SP - equals - 32 core Epyc 7601.
Amazing. Really amazing.
gescom - Tuesday, November 28, 2017 - link
Huh, I forgot - and that is Skylake at 130W vs Epyc at 180W.ddriver - Tuesday, November 28, 2017 - link
Gromacs is a very narrow niche product and also very biased - they heavily optimize for intel and nvidia and push amd products to take an inefficient code path.HStewart - Tuesday, November 28, 2017 - link
This is comparison with AVX2 / AVX512AVX512 is twice as wide as AVX2 and significant more power than the AVX2 - so yes it very possible in this this test that CPU with 1/4 the normal CPU cores can have more power because AVX512.
Also I heard AMD's implementation of AVX2 is actually two 128 bits together - these results could show that is true.