Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Introducing Skylake-SP: The Xeon Scalable Processor Family
The biggest news hitting the streets today comes from the Intel camp, where the company is launching their Skylake-SP based Xeon Scalable Processor family. As you have read in Ian's Skylake-X review, the new Skylake-SP core has been rather significantly altered and improved compared to it's little brother, the original Skylake-S. Three improvements are the most striking: Intel added 768 KB of per-core L2-cache, changed the way the L3-cache works while significantly shrinking its size, and added a second full-blown 512 bit AVX-512 unit.

On the defensive and not afraid to speak their mind about the competition, Intel likes to emphasize that AMD's Zen core has only two 128-bit FMACs, while Intel's Skylake-SP has two 256-bit FMACs and one 512-bit FMAC. The latter is only useable with AVX-512. On paper at least, it would look like AMD is at a massive disadvantage, as each 256-bit AVX 2.0 instruction can process twice as much data compared to AMD's 128-bit units. Once you use AVX-512 bit, Intel can potentially offer 32 Double Precision floating operations, or 4 times AMD's peak.
The reality, on the other hand, is that the complexity and novelty of the new AVX-512 ISA means that it will take a long time before most software will adopt it. The best results will be achieved on expensive HPC software. In that case, the vendor (like Ansys) will ask Intel engineers to do the heavy lifting: the software will get good AVX-512 support by the expensive process of manual optimization. Meanwhile, any software that heavily relies on Intel's well-optimized math kernel libraries should also see significant gains, as can be seen in the Linpack benchmark.
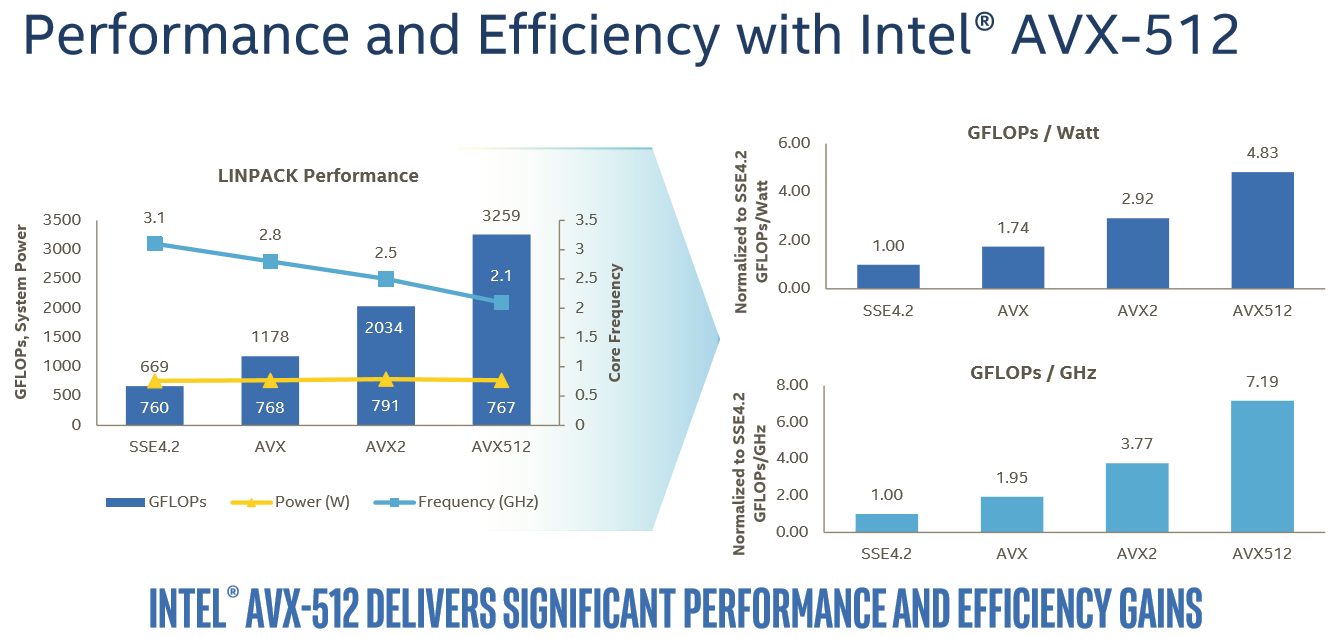
In this case, Intel is reporting 60% better performance with AVX-512 versus 256-bit AVX2.
For the rest of us mere mortals, it will take a while before compilers will be capable of producing AVX-512 code that is actually faster than the current AVX binaries. And when they do, the result will be probably be limited, as compilers still have trouble vectorizing code from scratch. Meanwhile it is important to note that even in the best-case scenario, some of the performance advantage will be negated by the significantly lower clock speeds (base and turbo) that Intel's AVX-512 units run at due to the sheer power demands of pushing so many FLOPS.

For example, the Xeon 8176 in this test can boost to 2.8 GHz when all cores are active. With AVX 2.0 this is reduced to 2.4 GHz (-14%), with AVX-512, the clock tumbles down to 1.9 GHz (another 20% lower). Assuming you can fill the full width of the AVX unit, each step still sees a significant performance improvement, but AVX2 to AVX-512 won't offer a full 2x performance improvement even with ideal code.
Lastly, about half of the major floating point intensive applications can be accelerated by GPUs. And many FP applications are (somewhat) limited by memory bandwidth. While those will still benefit from better AVX code, they will show diminishing returns as you move from 256-bit AVX to 512-bit AVX. So most FP applications will not achieve the kinds of gains we saw in the well-optimized Linpack binaries.








219 Comments
View All Comments
StargateSg7 - Sunday, August 6, 2017 - link
Maybe I'm spoiled, but to me a BIG database is something I usually deal with on a daily basissuch as 500,000 large and small video files ranging from two megabytes to over a PETABYTE
(1000 Terabytes) per file running on a Windows and Linux network.
What sort of read and write speeds do we get between disk, main memory and CPU
and when doing special FX LIVE on such files which can be 960 x 540 pixel youtube-style
videos up to full blown 120 fps 8192 x 4320 pixel RAW 64 bits per pixel colour RGBA files
used for editing and video post-production.
AND I need for the smaller files, total I/O-transaction rates at around
OVER 500,000 STREAMS of 1-to-1000 64 kilobyte unique packets
read and written PER SECOND. Basically 500,000 different users
simultaneously need up to one thousand 64 kilobyte packets per
second EACH sent to and read from their devices.
Obviously Disk speed and network comm speed is an issue here, but on
a low-level hardware basis, how much can these new Intel and AMD chips
handle INTERNALLY on such massive data requirements?
I need EXABYTE-level storage management on a chip! Can EITHER
Xeon or EPyC do this well? Which One is the winner? ... Based upon
this report it seems multiple 4-way EPyC processors on waterblocked
blades could be racked on a 100 gigabit (or faster) fibre backbone
to do 500,000 simultaneous users at a level MUCH CHEAPER than
me having to goto IBM or HP for a 30+ million dollar HPC solution!
PixyMisa - Tuesday, July 11, 2017 - link
It seems like a well-balanced article to me. Sure the DB performance issue is a corner case, but from a technical point of view its worth knowing.I'd love to see a test on a larger database (tens of GB) though.
philehidiot - Wednesday, July 12, 2017 - link
It seems to me that some people should set up their own server review websites in order that they might find the unbiased balance that they so crave. They might also find a time dilation device that will allow them to perform the multitude of different workload tests they so desire. I believe this article stated quite clearly the time constraints and the limitations imposed by such constraints. This means that the benchmarks were scheduled down to the minute to get as many in as possible and therefore performing different tests based on the results of the previous benchmarks would have put the entire review dataset in jeopardy.It might be nice to consider just how much data has been acquired here, how it might have been done and the degree of interpretation. It might also be worth considering, if you can do a better job, setting up shop on your own and competing as obviously the standard would be so much higher.
Sigh.
JohanAnandtech - Thursday, July 13, 2017 - link
Thank you for being reasonable. :-) Many of the benchmarks (Tinymembench, Stream, SPEC) etc. can be repeated, so people can actually check that we are unbiased.Shankar1962 - Monday, July 17, 2017 - link
Don't go by the labs idiotUnderstand what real world workloads are.....understand what owning an entire rack means ......you started foul language so you deserve the same respect from me......
roybotnik - Wednesday, July 12, 2017 - link
EPYC looks extremely good here aside from the database benchmark, which isn't a useful benchmark anyways. Need to see the DB performance with 100GB+ of memory in use.CarlosYus - Friday, July 14, 2017 - link
A detailed and unbiased article. I'm awaiting for more tests as testing time passes.3.2 Ghz is a moderate Turbo for AMD EPYC, I think AMD could push it further with a higher thermal envelope i/o 14 nm process improvement in the coming months.
mdw9604 - Tuesday, July 11, 2017 - link
Nice, comprehensive article. Glad to see AMD is competitive once again in the server CPU space.nathanddrews - Tuesday, July 11, 2017 - link
"Competitive" seems like an understatement, but yes, AMD is certainly bringing it!ddriver - Tuesday, July 11, 2017 - link
Yeah, offering pretty much double the value is so barely competitive LOL.