Exploring DynamIQ and ARM’s New CPUs: Cortex-A75, Cortex-A55
by Matt Humrick on May 29, 2017 12:00 AM EST- Posted in
- Smartphones
- CPUs
- Arm
- Mobile
- Cortex
- DynamIQ
- Cortex A75
- Cortex A55
DynamIQ
Before we discuss the new CPUs, we need to discuss DynamIQ. Introduced 5 years ago, ARM’s original big.LITTLE (bL) technology, which allows multiple clusters of up to 4 CPUs to be chained together, has been massively successful in the marketplace, allowing various combinations of its Cortex-A family of CPUs to power mobile devices ranging from the budget-friendly with no frills to the budget-busting flagships stuffed with technology. The combination of Cortex-A and bL extends beyond smartphones and tablets too, with applications ranging from servers to automotive.
Over the years, ARM’s IP and the needs of its customers have evolved, necessitating a new version of bL: DynamIQ. ARM started working on DynamIQ in 2013 by asking a single question: “How do you make big.LITTLE better?” Looking forward, ARM could see DynamIQ needed to be more flexible, more scalable, and offer better performance. Considering how much work went into this project, DynamIQ will be around for at least the next few years, so hopefully it delivers on those goals.

Like bL, DynamIQ provides a way to group CPUs into clusters and connect them to other processors and hardware within the system; however, there’s several significant changes, starting with the ability to place big and little Cortex-A CPUs in the same cluster. With bL, different CPUs had to reside within separate clusters. What appears to be a simple reshuffling of cores actually impacts CPU performance and configuration flexibility.
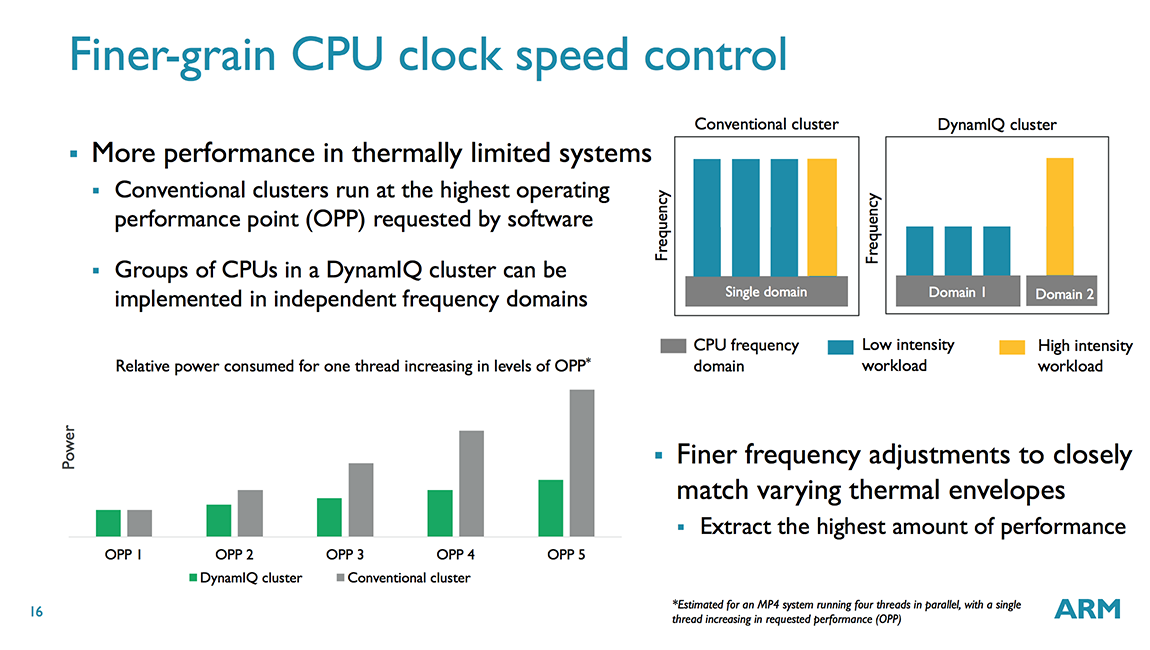
Another big change is the ability to place up to 8 CPUs inside a single cluster (up from 4 for bL), with the total number of CPUs scaling up to 256 with 32 clusters, which can scale even further to 1000s of CPUs with multi-chip support provided via a CCIX interface. Within a cluster CPUs are divided into voltage/frequency domains, and within a domain each core is inside its own power domain. This allows each CPU to be individually powered down, although all CPUs in the same domain must operate at the same frequency, which is no different from bL; however, with DynamIQ each cluster can support up to 8 voltage/frequency domains, providing greater flexibility than bL’s single voltage/frequency domain per cluster. So, what does this mean? It means that, in theory, an SoC vendor could place each CPU into its own voltage domain so that voltage/frequency could be set independently for each of the 8 CPUs in the cluster. Each voltage/frequency domain requires its own voltage regulator, which adds cost and complexity, so we’ll most likely continue to see 2-4 CPUs per domain.
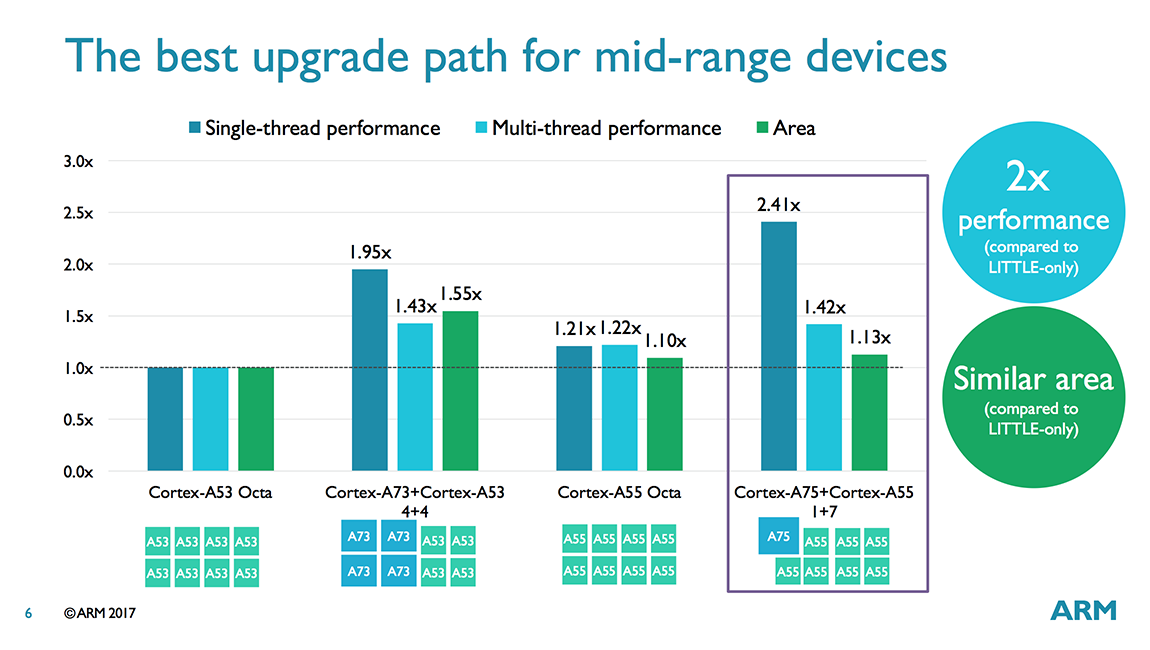
ARM still sees 8-core configurations being used in mobile devices over the next few years. With bL, this would likely be a 4+4 pairing using 4 big cores and 4 little cores or 8 little cores spread across 2 clusters. With DynamIQ, all 8 cores can fit inside a single cluster and can be split into any combination (1+7, 2+6, 3+5, 4+4) of A75 and A55 cores. ARM sees the 1+7 configuration, where one A55 core is replaced by a big A75 core, as particularly appealing for the mid-range market, because it offers up to 2.41x better single-thread performance and 1.42x better multi-thread performance for only a 1.13x increase in die area compared to an octa-core A53 configuration (iso-process, iso-frequency).
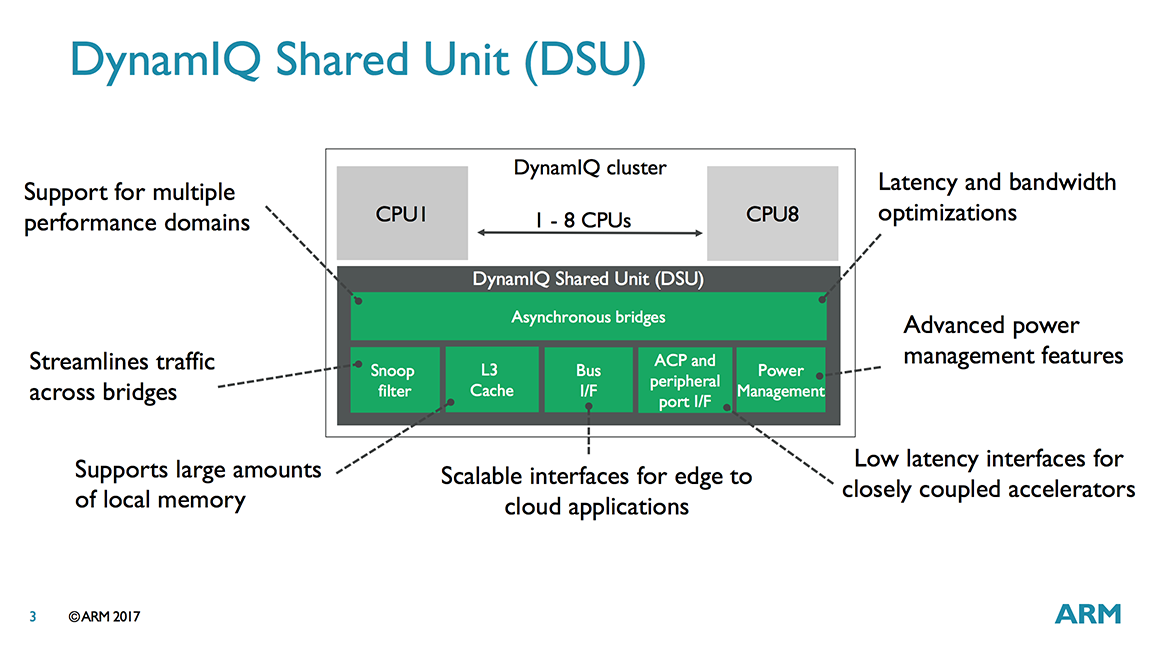
The main puzzle piece that enables this flexibility is the DynamIQ Shared Unit (DSU), a separate block that sits inside each DynamIQ cluster and functions as a central hub for the CPUs within the cluster and the bridge to the rest of the system. Each voltage/frequency domain in the cluster can be configured to run synchronously or asynchronously with the DSU. Using asynchronous bridges (one per domain) allows different CPUs (A75/A55) to operate at different frequencies (using synchronous bridges would force all CPUs to operate at the same frequency).
The DSU communicates with a CCI, CCN, or CMN cache-coherent interconnect through 1 to 2 128-bit AMBA 5 ACE ports or a single 256-bit AMBA 5 CHI port. There’s also an Accelerated Coherency Port (ACP) for attaching specialized accelerators that require cache coherency with the CPUs. It’s also used for enabling DynamIQ’s cache stashing feature, which we’ll discuss in a minute. Finally, there’s a separate peripheral port that’s used to program the accelerators attached to the ACP interface (basically a shortcut for programming transactions so they do not need to be routed through the system interconnect).

So far we’ve discussed DynamIQ’s flexibility and scalability features, but it also improves CPU performance through a new cache topology. With bL, CPUs inside a cluster had access to a shared L2 cache; however, DynamIQ compatible CPUs (currently limited to A75/A55) have private L2 caches that operate at the CPU core’s frequency. Moving the L2 closer to the core improves L2 cache latency by 50% or more. DynamIQ also adds another level of cache: The optional shared L3 cache lives inside the DSU and is 16-way set associative. Cache sizes are 1MB, 2MB, or 4MB, but may be omitted for certain applications like networking. The L3 cache is technically pseudo-exclusive, but ARM says it’s really closer to being fully-exclusive, with nearly all of the L3’s contents not appearing in the L2 and L1 caches. If the new L3 cache was inclusive, meaning that it contained a copy of a CPU’s L2, then its performance benefit would be largely mitigated and a lot of area and power would be wasted.

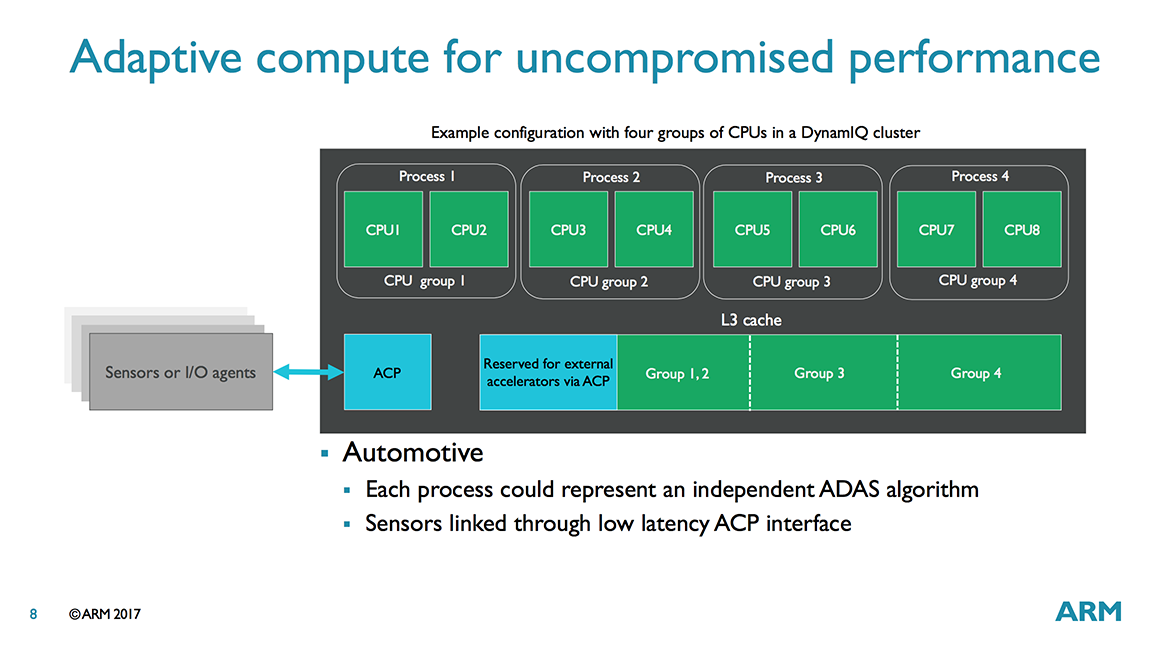
The L3 cache can be partitioned, which can be useful for networking or embedded systems that run a fixed workload or applications that require more deterministic data management. It can be partitioned into a maximum of 4 groups, and the split can be unbalanced, so 1 CPU could get 3MB while the other 7 CPUs would share the remaining 1MB in an 8-core 4MB L3 configuration. Each group can be assigned to specific CPU(s) or external accelerators attached to the DSU via the ACP or other interface. Any processors not specifically assigned to a cache group share the remaining L3 cache. The partitions are dynamic and can be created/adjusted during runtime by the OS or hypervisor.
One of the features supported by DynamIQ is error reporting, which allows the system to report detected errors, both correctable and uncorrectable, to software. The L3 supports ECC/parity (actually all levels of cache and snoop filters do, with SECDED on caches that can hold dirty data and SED parity on caches that only hold clean data) in order to be ASIL-D compliant. The L3 also has persistent error correction and can support recovery from a single hard error (data poisoning is supported at a 64-bit granularity).
Another new feature is cache stashing, which allows a GPU or other specialized accelerators and I/O agents to read/write data into the shared L3 cache or directly into a specific CPU’s L2 cache via the ACP or AMBA 5 CHI port. A specific example is a networking appliance that uses a TCP/IP offload engine to accelerate packet processing. Instead of writing its data to system memory for the CPU to fetch or relying on some other cache coherency mechanism, the accelerator could use cache stashing to write its data directly into the CPU’s L2, increasing performance and reducing power consumption.
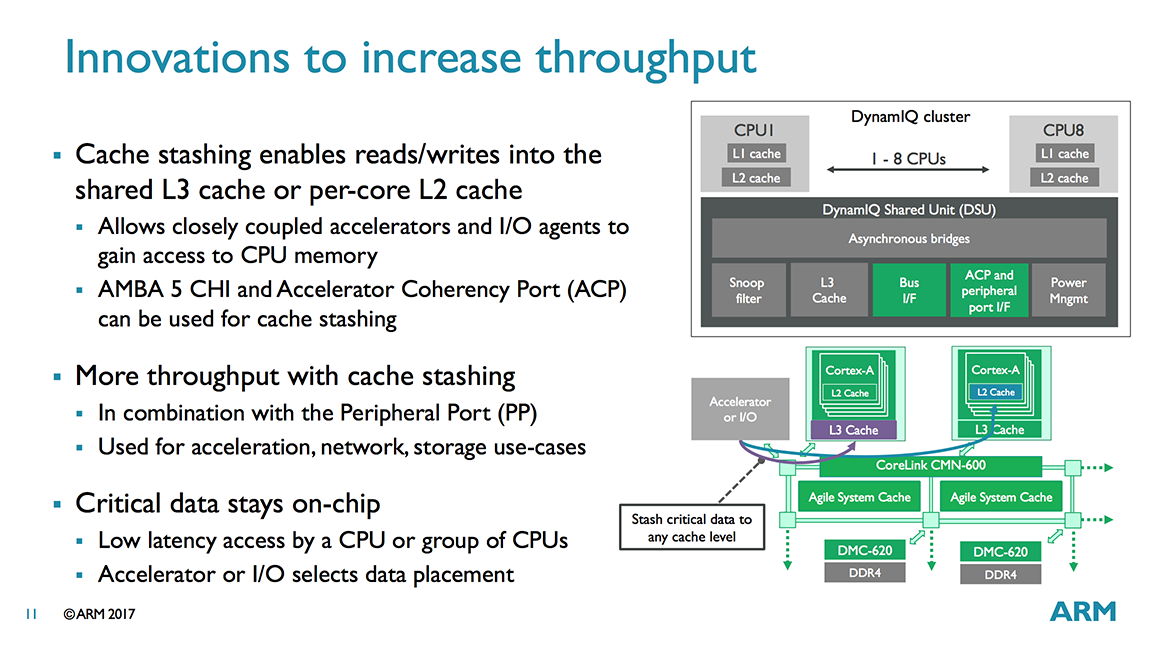
In order to use cache stashing, the software drivers running in kernel space need to be aware of the processor and cache topology, which will require custom code to enable hardware outside the cluster to access the shared L3 or an individual CPU’s L2. While a limitation for consumer electronics where time to market is key, it’s not as serious of an issue for commercial applications.
While cache stashing could be a useful feature for sharing data with processors sitting outside the cluster, DynamIQ also makes it easier to share data among CPUs within a cluster. This is one of the reasons why ARM wanted to bring big and little CPUs into the same cluster. Moving cache lines within a DynamIQ cluster is faster than moving them between clusters like with bL, reducing latency when migrating threads between big and little cores.

DynamIQ also includes improved power management. Having the DSU perform all cache and coherency management in hardware instead of software saves several steps when changing CPU power states, allowing the CPU cores to power up or down much faster than before with bL. The DSU can also power down portions of the L3 cache to reduce leakage power by autonomously monitoring cache usage and switching between full on, half off, and full off states.
The DSU includes a Snoop Control Unit (SCU) with an integrated snoop filter for handling the new cache topology. Together with L3 cache and other control logic, the DSU is about the same area as an A55 core in its max configuration or half the area of an A55 in its min configuration. These are just rough estimates because most of the DSU area is used by the L3 cache and the size of the DSU logic scales with the number of CPU cores.
Some of ARM’s partners may be slow to migrate from bL to DynamIQ, choosing to stick with a technology and CPU cores they are familiar with instead of investing the extra time and money required to develop new solutions. But for performance (and marketing) sensitive markets that need access to ARM’s latest CPU cores, such as mobile, the switch to DynamIQ should happen quickly, with the first DynamIQ SoCs likely to appear by the end of 2017 or early 2018.








104 Comments
View All Comments
lilmoe - Monday, May 29, 2017 - link
All of ARM's hope of having any significant, mainstream, server market share was demolished with the announcement of Naples.Wilco1 - Monday, May 29, 2017 - link
Check https://community.arm.com/processors/b/blog/posts/... - at the end there is a whole section on how much faster Cortex-A75 is compared to Cortex-A72 on SPECrate in big server designs. And Cortex-A55 also has all the RAS features required for servers.lilmoe - Monday, May 29, 2017 - link
It's about damn time they're addressing the little cores. We might not get anything better until they go fully OoO on both clusters with 7nm and beyond.Meteor2 - Monday, May 29, 2017 - link
In-order is more efficient, and that's important for 'workhorse' cores, whatever the node. Why waste energy when you don't need to? Like A53, A55 is about doing enough work quick enough, not doing as much as possible as fast as possible. (I think A35 was too weedy for life outside of IoT.)Plus I suspect that the ARM ISA is suited to in-order.
lilmoe - Monday, May 29, 2017 - link
Energy consumption goes down with each process node advancement. The A53 is spending most of its compute time well over 1.2ghz on flagship SoCs. At 1.5ghz and beyond, it starts wasting more energy than the big cluster at similar performance points. Your point is absolutely correct in an "ideal workload", but the real world is far from that with higher resolution screens and all the other crazy peripherals OEMs employ. We'll have to wait and see the performance energy curve first before determining the sweet spot of the a55 vs where most of the actual workload resides.Meteor2 - Friday, June 2, 2017 - link
Haven't seen an energy/performance curve on Anandtech for ages :(nandnandnand - Monday, May 29, 2017 - link
Low tier tech news outlets are saying the A75 has 50% more performance and that the A55 is 2.5x more power efficient:Compare: https://venturebeat.com/2017/05/28/arm-wants-to-bo... which acknowledges "in some use cases"
To: http://www.zdnet.com/article/arm-launches-new-cort... which just says "up to"
50% figure comes from comparing A73 at 2.4 GHz to A75 at 3.0 GHz: https://www.theregister.co.uk/2017/05/29/arm_cpus_...
jjj - Monday, May 29, 2017 - link
The 2.5x claim was on an ARM slide but it included process shrinks.The 50% claim seems to be at 2W per core not 3GHz but even then it clearly isn't in SPEC,maybe in Geekbench it gets close to that gain at 2W.
Krysto - Monday, May 29, 2017 - link
I wouldn't be surprised if we do see some configurations at 7nm like that (3GHz). ARM has always tended to give pretty unrealistic clock speed peak performance for its cores, which no chip maker actually ended up implementing, but I think this time it may be different due to Chromebooks and Windows 10 on ARM, where a 15W TDP or even higher is perfectly fine, as long as you also get good performance/W (compared to Intel/AMD).However, chip makers and OEMs will also have to take into account Windows 10 on ARM emulation, so they'll need to keep those chips at least 10% lower TDP/power consumption than the Intel/AMD competitors at those levels of performance.
jjj - Monday, May 29, 2017 - link
A75 is not aimed at 7nm, that's where the next core comes in.