Launching the #CPUOverload Project: Testing Every x86 Desktop Processor since 2010
by Dr. Ian Cutress on July 20, 2020 1:30 PM EST
One of the most visited parts of the AnandTech website, aside from the reviews, is our benchmark database Bench. Over the last decade we've placed in there as much benchmark data as we can for every sample we can get our hands on: CPU, GPU, SSD, Laptop and Smartphone being our key categories. As the Senior CPU editor here at AnandTech, one of my duties is to maintain the CPU part of Bench, making sure the benchmarks are relevant and the newest components are tested with benchmark data up to date as much as possible. Today we are announcing the start of a major Bench project with our new Benchmark suite, and some very lofty goals.
What is Bench?
A number of our regular readers will know Bench. We placed a link to easily access it at the top of the page, although given the depth of content it holds, is an understated part of AnandTech. Bench is the centralized database where we place all of the benchmark data we gather for processors, graphics, storage, tablets, laptops and smartphones. Internally Bench has many uses, particularly when collating review data to generate our review graphs, rather than manually redrawing full data sets for each review or keeping datasets offline.
But the biggest benefit with Bench is to either compare many products in one benchmark, or compare two products across all our benchmark tests. For example, here are the first few results of our POV-Ray test.
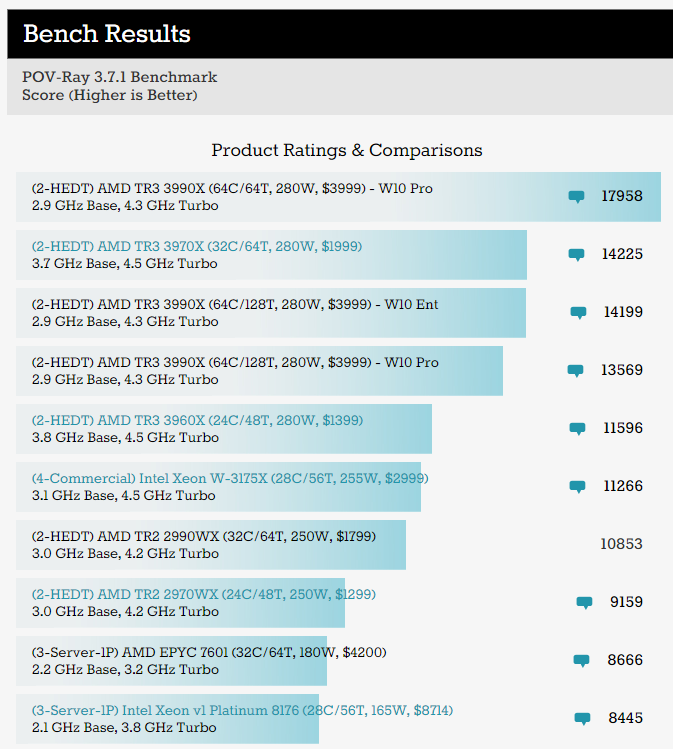
At its heart, Bench is a comparison tool, with the ability to square two products off side by side can be vital when choosing which one to invest in. Rather than just comparing specifications, Bench provides real world data, offering 3rd party independent verification of data points. In contrast to the benchmarks other companies that are invested in selling you the product might provide, we try and create benchmarks that actually mean something, rather than just list the synthetics.
The goal of Bench has always been a regressive comparison, comparing what the user has to what the user might be looking at purchasing. As a result of a decade of data, that 3-5 year generational gap of benchmark information can become vital to actually quantifying how much of an upgrade a user might receive on the CPU alone. It all depends on what products already have benchmark data in the database, and if the benchmarks are relevant to the workflow (web, office, rendering, gaming, workstation tests, and so on).
Bench: The Beginning
Bench originally started over a decade ago by the founder of AnandTech, Anand. On the CPU side of the database, he worked with both AMD and Intel to obtain a reasonable number of the latest CPUs of the day, and then spent a good summer testing them all. This happened back when Core 2 and Athlons were running the market, with a number of interesting comparisons. The beauty of the Bench database is that all the data from the 30 or so processors Anand tested way back then still exists today, with the core benchmarks of interest to the industry and readership at the time.
With AMD and Intel providing the processors they did, testing every processor became a focal point for the data: it allowed users to search for their exact CPU, compare it to other models in the same family that differ on price, or compare the one they already have to a more modern component they were thinking of buying.
As the years have progressed, Bench has been updated with all the review samples we could obtain and have time to put through the benchmarks. When a new product family is launched however, we rarely get to test them all - unfortunately official sampling rarely goes beyond one or two of the high end products, or if we were lucky, maybe a few more. While we’ve never been able to test full processor stacks from top to bottom, we have typically been able to cover the highlights of a product range, and it has still allowed users to perform general comparisons using the data and for users looking to upgrade their three year old components.
Two main factors have always inhibited the expansion of Bench.
Bench Problem #1: Actually Getting The Hardware
First, the act of sourcing the components can be a barrier to obtaining benchmark data. If we do not have the product, we cannot run the benchmarks! Intel and AMD (and VIA, back in the day) have had different structures for sampling their products, depending on how much they want to say, the release time frame, and the state of the market. Other factors can include the importance of certain processors to the financials of a company, or level of the relationship between us and the manufacturers. Intel and AMD will only work with review websites at any depth if the analysis is fair, and our readers (that’s you) would only read the data if the analysis was unbiased as well.
When it comes down to the base media sampling strategies, companies can typically take two routes. The nature of the technology industry is down to Press Relations (PR), and most companies will have both internal PR departments and also outsource local PR to companies that specialize in that region. Depending on the product, sampling can occur either direct from the manufacturer or via the local PR team, and the sampling strategy will be pre-determined at a much higher level: how many media websites are to be sampled, how many samples will be distributed to each region etc. For example, if a product is going to be sampled via local PR only, there might only be 3-5 units for 15+ technology media outlets, requiring that the samples be moved around when they have been tested. Some big launches, or depending on the relationship between the media outlet with the manufacturer, will be managed from the company internal global PR team, where samples are provided in perpetuity: essentially on long-term loans (which could be recalled).
For the x86 processor manufacturers, Intel and AMD are the players we work with. Of late, Intel’s official media sampling policy provides the main high-end processor in advance of the processor release, such as the i7-4770K, or the i7-6700K. On rare occasions, one of the lower down parts down the stack are provided at the same time, or made available for sampling after the launch date. For example, with the latest Comet Lake, we were sampled both the i9-10900K and the i5-10600K, however these are both high-impact overclockable CPUs. This typically means that if there's an interesting processor down the stack, such as an i3-K or a low cost Pentium, then we have to work with other partners to get a sample (such as motherboard manufacturers, system integrators, or OEMs), or outright purchase it internally.

For AMD’s processors, as demonstrated over the last 4-5 years, the company does not often release a full family stack of CPUs at one time. Instead, processors are launched in batches, with AMD choosing to do two or three every few months. For example, AMD initially launched Ryzen with the three Ryzen 7 processors, followed by four Ryzen 5 processors a few weeks later and finally two Ryzen 3 parts. With the past few generations from AMD, depending on how many processors are in the final stack of CPUs, AnandTech is usually sampled most of them, such as with 1st Gen Ryzen where we were sampled all of them. Previously with the Richland and Trinity processors, only around half the stack were initially offered for review, and less chance of being sampled for the lower value parts, or some parts were offered through local PR teams a couple of months after launch. AMD still today launches OEM parts for specific regions - it tends not to sample those to press either, especially if the press are not in the region for that product.
With certain processors, they target certain media organizations that prioritize different elements of testing, which lends to an imbalance of which media get which CPUs. Most manufacturers will rate the media outlets they work with into tiers, with the top tier ones getting earlier sampling or more access to the components. The reason for this is that if a company sampled everyone everything every time, suddenly 5000 media outlets (and anyone who wants to start a component testing blog) would end up with 10-25 products on their doorstep every year and it would be a mammoth task to organize (for little gain from the outlets with fewer readers).
The concept of tiering is not new – it depends on the media outlets readership reach, the demographic, and the ability to understand the nuance of what is in their hands. AMD and Intel can't sample everyone everything, and sometimes they have specific markets to target, which will also shift focus on who will get what samples. A website focused on fanless HTPCs for example would not be a preferred sampling vector for workstation class processors. At AnandTech, we cover a broad range of topics, have educated readers, and have been working with Intel and AMD for twenty years. On the whole, we generally do well when it comes to processor sampling, although there are still limits - going out and asking for a stack of next generation Xeon Gold CPUs is unlikely to be as simple as overnight shipping.
Bench Problem #2: The March of Time
The second problem with the benchmark database is timing and benchmarks. This comes down to manpower – how many people are running the benchmarks, and the timeframes for which the benchmarks we do test remain relevant for the segments of our readers that are interested in the hardware.
Take graphics card testing, for example: GPU drivers change monthly, and games are updated every few months (and the games people are playing also change). To keep a healthy set of benchmark data, it requires retesting 5 graphics cards per GPU vendor generation, 4-5 generations of GPU launches, from 3-4 different board partners, on 6-10 games every month at three different resolutions/settings per game (and testing each combination enough to be statistically accurate). That takes time, significant effort, and manpower, and I’m amazed Ryan has been able to do so much in the little time he has being the Editor-in-Chief. Picking the highest numbers out of those ranges gives us 5 (GPUs) x 2 (vendors) x 5 (generations) x 4 (board partners) x 10 (games) x 3 (resolutions) x 4 (statistically significant) results, which comes to 24000 benchmark runs, out of the door each month, in an ideal scenario. You could be halfway through and someone issues a driver update, making the rest of the data for naught. It’s not happening overnight, and arguably that could be work for at least one full time employee if not two.

On the CPU side of the equation, the march of time is a little slower. While the number of CPUs to test can be higher (100+ consumer parts in the last few generations), the number of degrees of freedom is smaller, and the rate of our CPU benchmark refresh cycles can be longer. These parameters depend on OS updates and drivers like the GPU testing, but it means that some benchmarks can still be relevant several years later with the same operating system base. 30 year old legacy Fortran code still in use is likely going to stay 30 year old legacy Fortran code in the near future. Or even benchmarks like CineBench R15 are still quoted today, despite the Cinema4D software on which it is based is several generations newer. The CPU testing ends up ultimately limited by the gaming tests, and depends on which modern GPUs are used, what games are being tested, what resolutions are relevant, or when new benchmarks enter the fray.
When Ryan retests a GPU, he has a fixed OS, system ready to go, updates the drivers, and puts the GPU back into the slot. Preparing a new CPU platform for new benchmarks means rebuilding the full system, reinstalling the OS, reinstalling the benchmark suite, and then testing it. However, with the right combination of hardware and tests, a good set of data can last 18 months or so without significant updates. The danger is that whenever there is a full benchmark refresh, which especially revolves around updates to newer operating systems. Due to how OS updates and scheduling with the software stack effects the new operating system, all the old data cannot be compared and the full set of hardware has to be retested on the new OS with an updated benchmark suite.
With our new CPU Overload project (stylized as #CPUOverload in our article titles, because social media is cool?), the aim is to get around both of these major drawbacks.
What is #CPUOverload?
The seeds of this project were initially sown several years ago in 2016. Despite having added our benchmark data to Bench for several years, I had kind of known our Benchmark database was a popular tool, but I didn't really realize how much it was used, or more precisely, under optimized, until recently when I was given access to be able to dig around in our back-end data.
Everyone shopping for a processor wants to know how good the one they're interested in is, and how much of a jump in performance they'll get from their old part. Reading reviews is all well and good, but due to style and applicability, only a few processors are directly compared in a review to a different part specifically, otherwise the review could be a hundred pages long. There have been many times where Ryan has asked me to scale back from 30000 data points in a review!
Also it’s worth noting that reviews are often not updated with newer processor data, as there would be a factual disconnect with the textual analysis underneath.
This is why Bench exists. We often link in each review to Bench and request users go there to compare other processors, or for legacy benchmarks / benchmark breakdowns that are not in the main review.
But for #CPUOverload, with the ongoing march of Windows 10, and the special features therein (such as enabling Speed Shift on Intel processors, new scheduler updates for ACPI 6.2, and having the driver model to support DX12), it has been getting time for us to update our CPU test suite. Our recent reviews were mostly being criticized for still using older hardware, namely the GTX 1080s that I was able to procure, along with having some tests that didn’t always scale with the CPU. (It is worth noting that alongside sourcing CPUs for testing, sourcing GPUs is somewhat harder - asking a vendor or the GPU manufacturer for two or three or more of the same GPU without a direct review is a tough ask.) The other angle is that in any given month, I will get additional requests to benchmark specific CPU tests – users today would prefer seeing their workload in action for comparison, rather than general synthetics, for obvious reasons.
There is also a personal question of user experience on Bench, which has not aged well since our last website layout update in 2013.
In all, the aims of CPU Overload are:
- Source all CPUs. Focus on ones that people actually use
- Retest CPUs on Windows 10 with new CPU tests
- Retest CPUs on Windows 10 with new Gaming tests
- Update the Bench interface
For the #CPUOverload project, we are testing under Windows 10, with a variety of new tests, including AI and SPEC, with new gaming tests on the latest GPUs, and more relevant real world benchmarks. But the heart of CPU Overload is this:








110 Comments
View All Comments
ruthan - Monday, July 27, 2020 - link
Well lots of bla, bla, bla.. I checked graphs in archizlr they are classic just few entries.. there is link to your benchmark database, but here i see preselected some Crysis benchmark, which is not part of article.. and dont lead to some ultimate lots of cpus graphs. So it need much more streamlining.i usually using old Geekbench for cpus tests and there i can compare usually what i want.. well not with real applications and games, but its quick too. Otherwise usually have enough knowledge to know if is some cpu good enough for some games or not.. so i dont need some very old and very need comparisions. Something can be found at Phoronix.
These benchmarks will always lots relevancy with new updates, unless all cpus would in own machines and update and running and reresting constantly - which could be quite waste of power and money.
Maybe some golden path is some simple multithreaded testing utility with 2 benchmarks one for integers and one for floats.
Ian Cutress - Wednesday, August 5, 2020 - link
When you're in Bench, Check the drop down menu on your left for the individual testshnlog - Wednesday, July 29, 2020 - link
> For our testing on the 2020 suite, we have secured three RTX 2080 Ti GPUs direct from NVIDIA.Congrats!
Koenig168 - Saturday, August 1, 2020 - link
It would be more efficient to focus on the more popular CPUs. Some of the less popular SKUs which differ only by clock speed can have their performance extrapolated. Testing 900 CPUs sound nice but quickly hit diminishing returns in terms of usefulness after the first few hundred.You might also wish to set some minimum performance standards using just a few tests. Any CPU which failed to meet those standards should be marked as "obsolete, upgrade already dude!" and be done with them rather than spend the full 30 to 40 hours testing each of them.
Finally, you need to ask yourself "How often do I wish to redo this project and how much resources will I be able to devote to it?" Bearing in mind that with new drivers, games etc, the database needs to be updated oeriodically to stay relevant. This will provide a realistic estimate of how many CPUs to include in the database.
Meteor2 - Monday, August 3, 2020 - link
I think it's a labour of love...TrevorX - Thursday, September 3, 2020 - link
My suggestion would be to bench the highest performing Xeons that supported DDR3 RAM. Why? Because the cost of DDR3 RDIMMs is so amazingly cheap (as in, less than 10%) compared with DDR4. I personally have a Xeon E5-1660v2 @4.1GHz with 128GB DDR3 1866MHz RDIMMs that's the most rock stable PC I've ever had. Moving up to a DDR4 system with similar memory capacity would be eye-wateringly expensive. I currently have 466 tabs open in Chrome, Outlook, Photoshop, Word, several Excel spreadsheets, and I'm only using 31.3% of physical RAM. I don't game, so I would be genuinely interested in what actual benefit would be derived from an upgrade to Ryzen / Threadripper.Also very keen to see server/hypervisor testing of something like Xeon E5-2667v2 vs Xeon W-1270P or Xeon Silver 4215R for evaluation of on-prem virtualisation hosts. A lot of server workloads are being shifted to the cloud for very good reasons, but for smaller businesses it might be difficult to justify the monthly expense of cloud hosting (and Azure licensing) when they still have a perfectly serviceable 5yo server with plenty of legs left on it. It would be great to be able to see what performance and efficiency improvements can be had jumping between generations.
Tilmitt - Thursday, October 8, 2020 - link
When is this going to be done?Mil0 - Friday, October 16, 2020 - link
Well they launched with 12 results if I count correctly, and currently there are 38 listed, that's close to 10/month. With the goal of 900, that would mean over 7 years (in which ofc more CPUs would be released)Mil0 - Friday, October 16, 2020 - link
Well they launched with 12 results if I count correctly, and currently there are 44 listed, that's about a dozen a month. With the goal of 900, that would mean 6 years (in which ofc more CPUs would be released)Mil0 - Friday, October 16, 2020 - link
Caching hid my previous comment from me, so instead of a follow up there are now 2 pretty similar ones. However, in the mean time I found Ian is actually updating on twitter, which you can find here: https://twitter.com/IanCutress/status/131350328982...He actually did 36 CPU's in 2.5 months, so it should only take 5 years! :D