NVIDIA’s GeForce GTX 460: The $200 King
by Ryan Smith on July 11, 2010 11:54 PM EST- Posted in
- GPUs
- GeForce GTX 400
- GeForce GTX 460
- NVIDIA
The Rest of GF104
Besides adding superscalar dispatch abilities to GF104, NVIDIA has also made a number of other tweaks to the Fermi architecture for this GPU.
As a mid-range product, GF104 does not need to do 2 jobs at once. GF100 had to be usable as a desktop/professional graphics GPU, but also as a compute GPU for NVIDIA’s Tesla line of cards. GF104 will not be a Tesla product, so those compute abilities are not as critical. Specifically, NVIDIA has taken a chisel to Tesla’s flagship compute abilities of FP64 and ECC, which in GF100 desktop GPUs were artificially throttled and disabled respectively.
For GF104, ECC is completely gone. Barring the errant burst of solar radiation, the odds of a flipped bit or other error in the operation of a GPU is extremely slim. NVIDIA only added the feature for Tesla customers who demanded increased reliability as they could not accept a silent error in their work. For graphics however this is unnecessary, so the feature has been dropped.
Double-precision floating-point (FP64) on the other hand hasn’t been entirely dropped. Like ECC, FP64 is primarily a Tesla feature, but at the same time NVIDIA believes it to not be in their best interests to remove the feature. From NVIDIA’s perspective without FP64 on their consumer cards developers could not test and debug FP64 code on their desktops and laptops, which in turn would impede development for Tesla and hurt their efforts to expand in to the professional compute space. As a result GF104 has an interesting compromise on FP64.
For GF104, NVIDIA removed FP64 from only 2 of the 3 blocks of CUDA cores. As a result 1 block of 16 CUDA cores is FP64 capable, while the other 2 are not. This gives NVIDIA the advantage of being able to employ smaller CUDA cores for 32 of the 48 CUDA cores in each SM while not removing FP64 entirely. Because only 1 block of CUDA cores has FP64 capabilities and in turn executes FP64 instructions at 1/4 FP32 performance (handicapped from a native 1/2), GF104 will not be a FP64 monster. But the effective execution rate of 1/12th FP32 performance will be enough to effectively program in FP64 and debug as necessary.
Moving on, we have GF104’s texture units. GF100 was an interesting beast when it came to texturing, as it had texture units more efficient than GT200, but fewer of them overall. We don’t have any data that points to GF100 being absolutely deficient on texturing speeds, but at the same time it’s hard to imagine that GF100 was overbuilt to the point that losing 32 texture units wouldn’t hurt.
So for GF104, NVIDIA has doubled up on the number of texture units. A “full” GF104 has the same number of texture units at GF100 (64) in half as many SMs. NVIDIA tells us that this change is largely because texture units are small enough that they can be added without consuming too much additional die space, as opposed to requiring additional texture units such as a specific case of lacking texture performance or having too little texture performance relative to shading performance. But this isn’t something we can prove or disprove. High-detail settings optimized for high-end cards often go heavy on anti-aliasing or shading as opposed to textures, so ultimately we’re not surprised that NVIDIA kept the texture unit count constant while reducing the shader count in moving from GF100 to GF104. The shaders will be missed much less than the texture units would have been.
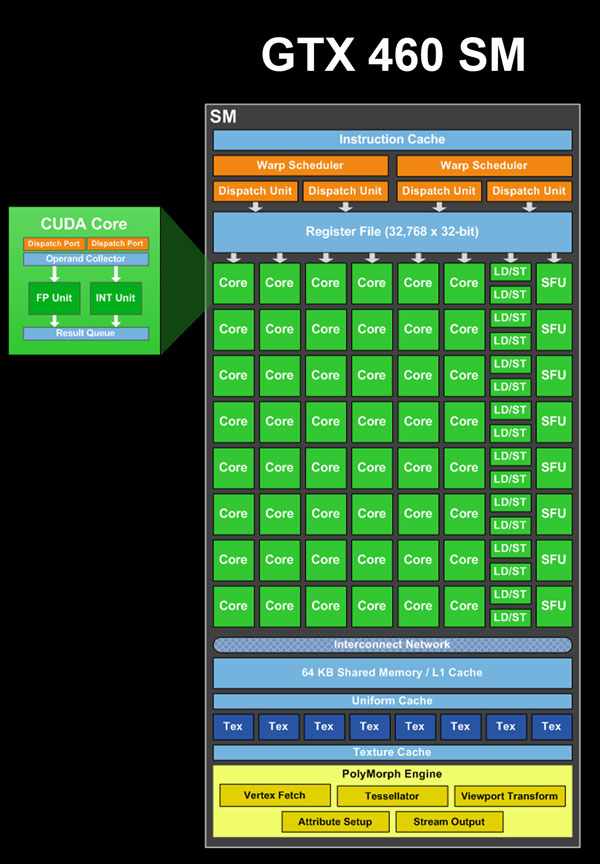
Finally, we have the ROPs. There haven’t been any significant changes here, but the ROP count does affect compute performance by impacting memory bandwidth and L2 cache. Even though NVIDIA keeps the same number of SMs on both the 1GB and 768MB of the GTX 460, the latter will have less L2 cache which may impact compute performance. Compute performance on the GTX 460 may also be impacted by pressure on the registers and L1 cache: NVIDIA increased the number of CUDA cores per SM, but not the size of the Register File or the amount of L1 cache/shared memory, so there are now additional CUDA cores fighting for the same resources. In the worst case scenarios, this can hurt the efficiency of GF104 compared to GF100.
For those of you who are curious, with all of these SM changes between GF100 and GF104 the size of a SM did increase, but by nearly as much as one would think: after adding the additional functional units, infusing the warp schedulers with superscalar dispatch capabilities, and removing unnecessary ECC and FP64 hardware, the size of an SM only increased by 25%. This is a tradeoff NVIDIA could not afford on the already massive GF100, but made sense on GF104 where the performance increase could justify the extra die space.








93 Comments
View All Comments
san1s - Monday, July 12, 2010 - link
I hope this is the card that finally brings price drops, they have been stagnant for far too long.JGabriel - Monday, July 12, 2010 - link
It should. The 768MB version seems to perform about 5% better than the 5830, and the 1GB version comes to ~90% of the 5850.
Just on a performance per dollar basis, that means ATI should drop the 5830 to $189 max, with somewhere in the $170-$180 range being more reasonable, and the 5850 needs to drop down to about $249. Basically, we should be looking at 10%-20% price cuts for the 5670, 5750, 5770, 5830, and 5850.
It should force the GTX 470 under $300, too.
.
medi01 - Monday, July 12, 2010 - link
Best way to drop prices would be to ramp up production. Now, if what I've heard is true (fab treats nVidia as a preferred customer, unlike AMD) we will get yet another round of unfair competition, which in the end will hurt us, customers. :(PS
Is it me, or articles on this side seem quite a bit to be more positive on what nVidia does, than what would feel neutral? Marketing hints like "it’s not a simple reduced version of GF100 like what AMD did" all over... :(
jonup - Monday, July 12, 2010 - link
It is you! Only need to go to the GTX465 review to disptove your point.teohhanhui - Monday, July 12, 2010 - link
Giving credit where it is due?nafhan - Monday, July 12, 2010 - link
Ryan said that because the GF104 isn't a simple reduced version of GF100. Did you notice the part of the article where they talked about superscalar processing? That's not only a marketing bullet point, it's a pretty big change from an architecture point of view, too!medi01 - Tuesday, July 13, 2010 - link
And this detail brings what particular benefit to the user? In particular, contrasting it with competitors (otherwise superior, cooler and faster) solution? Someone makes something wrong, then he has to rework it (the competitor, that did it right from the beginning, doesn't) and this somehow makes he deserve "some credit"?Ben90 - Monday, July 12, 2010 - link
About that "marketing" comment about not a shrink of GF100, its completely true and how does that make this site pro-NVIDIA?You should check out the next article; very first paragraph:
"In 2007 we reviewed NVIDIA’s GeForce 8800 GT. At the time we didn’t know it would be the last NVIDIA GPU we would outright recommend at launch."
medi01 - Tuesday, July 13, 2010 - link
It's completely true, yet it is confusing at best. Piece of silicon is "praised" for something, that has no practical value to the consumer.And please, don't compare nVidia article to nVidia article, compare it to AMD:
When 5830 was reviewed, and mind you, it's a nice card that runs cooler, has eyefinity, but is a tad slower than older 49xx, this fact was PUT INTO TITLE, mind you. It was mentioned in the very NAME of the article, that new 200$ card is a tad slower than older ones. (basically the only "bad thing" that one could say about the card)
In case of 465 it's barely mentioned "oh, it's slower than older 200$ cards".
=(
Lonyo - Tuesday, July 13, 2010 - link
Anandtech is a tech site that often goes more into the under the hood bits.On some sites you will see them calculating performance per currency numbers, or performance per watt.
On Anandtech you will have them discussing things like changes to the architecture, the way the threading works etc.
That's not a new thing, and it's not a biased thing, that's just what they do here at AT in their reviews. It just so happens that the GTX460 has some of those under the hood changes compared to the earlier cards based on the same architecture, so they are discussed in the article.
If you don't care too much about that sort of thing, you can just skip to the benchmarks. If you are interested in it, then it's a nice addition.