The Next Generation Open Compute Hardware: Tried and Tested
by Johan De Gelas & Wannes De Smet on April 28, 2015 12:00 PM ESTVisiting Facebook's Hardware Labs
We visited Facebook's hardware labs in September, an experience resembling entering the chocolate factory from Charlie and the Chocolate Factory; though the machinery was far less enjoyable to chew on. More importantly though, we were already familiar with the 'chocolate', in that by reading the specifications and following OCP related news, most of the systems present in their labs we could point out and name.

Wannes, Johan, and Matt Corddry, director of hardware of engineering in the Facebook Hardware labs
This symbolizes one of the ultimate goals for the Open Compute project: complete standardization of the datacenter out of commodity components that can be sourced from multiple vendors. And when the standards do not fit your exotic workload, you have a solid foundation to start from. This approach has some pleasant side effects: when working in an OCP powered datacenter, you could switch jobs to another OCP DC and just carry on doing sysadmin tasks -- you know the system, you have your tools. When migrating from a Dell to HP environment for example, the switch will be a larger hurdle due to differentiation by marketing.
Microsoft's Open Cloud Server v2 spec actually goes the extra mile by supplying you with an API specification and implementation in the Chassis controller, giving devops a REST API to manage the hardware.
Intel Decathlete v2, AMD Open 3.0, and Microsoft OCS
Facebook is not the only vendor to contribute open server hardware to open compute project either; Intel and AMD joined pretty soon after the OCP was founded, and last year Microsoft joined the party as well in a big way. The Intel Decathlete is currently in its second incarnation with Haswell support. Intel uses its Decathlete motherboards, which are compatible with ORv1, to build its reference 1U/2U 19" server implementations. These systems are seen in critical environments, like High Frequency Trading systems, where the customers want a server built by the same people who built the CPU and chipset, just so it all ought to work well together.
AMD has its Open 3.0 platform, which we detailed in 2013. This server platform is AMD's way of getting its foot in the door of OCP hyperscale datacenters, certainly when considering price. AMD seems to be taking a bit of a break improving its regular Opteron x86 CPUs, and we wonder if we might see the company bring its AMD Opteron-A ARM64 platform (dubbed 'Seattle') into the fold.
Microsoft brought us its Open Cloud Server (v2), systems that basically power all of Microsoft's cloud services (e.g. Azure), which is a high-density blade-like solution for standard 19" racks.
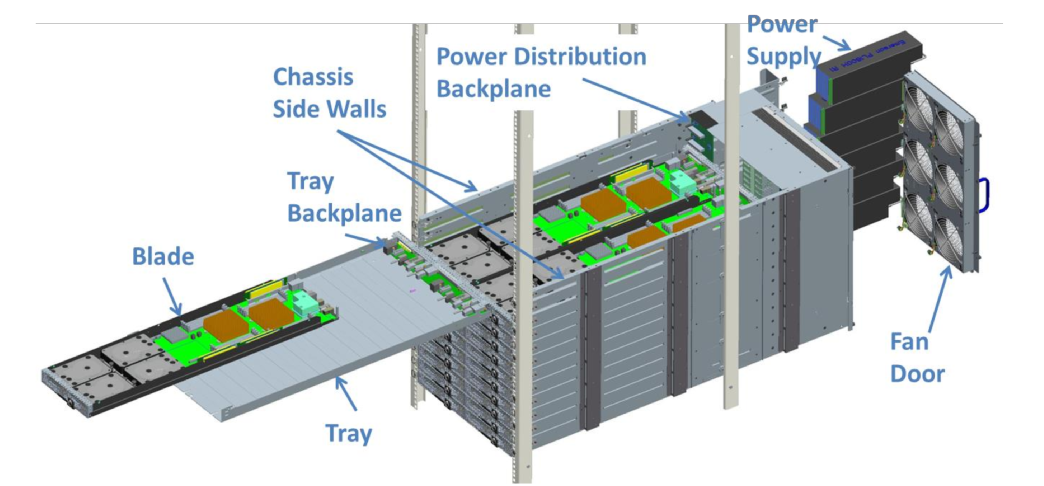
(Image Courtesy Microsoft)
A 12U chassis, equipped with 6 large 140x140mm fans, 6 power supplies, and a chassis manager module carries 24 nodes. Similar to Facebook's servers, there are two node types: one for compute, one for storage. A major difference however is that the chassis provides network connectivity at the back using a 40 QSFP+ port and a 10 SFP+ port for each node. The compute nodes mate with the connectors inside the chassis, the actual network cabling can remain fixed. The same principle is applied to the storage nodes, where the actual SAS connectors are found on the chassis, eliminating the need for cabling runs to connect the compute and JBOD nodes.
A V2 compute node comes with up two Intel Haswell CPUs, with a 120 Watt maximum thermal allowance, paired to the C610 chipset and with 16 DIMM DDR4 slots to share, for a total memory capacity of 512GB. Storage can be provided through one of the 10 SATA ports or via NVMe flash storage. The enclosure provides space for four 3.5" hard disks, four 2.5" SSDs (though space is shared between two of the bottom SSD slots), and a NVMe card. A mezzanine header allows you to plug in a network controller or a SAS controller card. Management of the node can be done through the AST1050 BMC providing standard IPMI functionality, in addition a serial console of each node is available at the chassis manager as well.
The storage node is a JBOD in which then 3.5" SATA III hard disks can be placed, all connected to a SAS expander board. The expander board then connects to the SAS connectors on the tray backplane, where they can be linked to a compute node.








26 Comments
View All Comments
Kevin G - Tuesday, April 28, 2015 - link
Excellent article.The efficiency gains are apparent even using suboptimal PSU for benchmarking. (Though there are repeated concurrency values in the benchmarking tables. Is this intentional?)
I'm looking forward to seeing a more compute node hardware based around Xeon-D, ARM and potentially even POWER8 if we're lucky. Options are never a bad thing.
Kind of odd to see the Knox mass storage units, I would have thought that OCP storage would have gone the BackBlaze route with vertically mount disks for easier hot swap, density and cooling. All they'd need to develop would have been a proprietary backplane to handle the Kinetic disks from Seagate. Basic switching logic could also be put on the backplane so the only external networking would be high speed uplinks (40 Gbit QSFP+?).
Speaking of the Kinetic disks, how is redundancy handled with a network facing drive? Does it get replicated by the host generating the data to multiple network disks for a virtual RAID1 redundancy? Is there an aggregator that handles data replication, scrubbing, drive restoration and distribution, sort of like a poor man's SAN controller? Also do the Kinetic drives have two Ethernet interfaces to emulate multi-pathing in the event of a switch failure (quick Googling didn't give me an answer either way)?
The cold storage racks using Blu-ray discs in cartridges doesn't surprise me for archiving. The issue I'm puzzled with is the process how data gets moved to them. I've been under the impression that there was never enough write throughput to make migration meaningful. For a hypothetical example, by the time 20 TB of data has been written to the discs, over 20 TB has been generated that'd be added to the write queue. Essentially big data was too big to archive to disc or tape. Parallelism here would solve the throughput problem but that get expensive and takes more space in the data center that could be used for hot storage and compute.
Do the Knox storage and Wedge networking hardware use the same PDU connectivity as the compute units?
Are the 600 mm wide racks compatible use US Telecom rack width equipment (23" wide)? A few large OEMs offer equipment in that form factor and it'd be nice for a smaller company to mix and match hardware with OCP to suit their needs.
nils_ - Wednesday, April 29, 2015 - link
You can use something like Ceph or HDFS for data redundancy which is kind of like RAID over network.davegraham - Tuesday, April 28, 2015 - link
Also, Juniper Networks has an ONIE-compliant OCP switch called the OCX1100 which is the only Tier1 switch manufacturer (e.g. Cisco, Arista, Brocade) to provide such a device.floobit - Tuesday, April 28, 2015 - link
This is very nice work. One of the best articles I've seen here all year. I think this points at the future state of server computing, but I really wonder if the more traditional datacenter model (VMware on beefy blades with a proprietary FC-connected SAN) can be integrated with this massively-distributed webapp model. Load-balancing and failovering is presumably done in the app layer, removing the need for hypervisors. As pretty as Oracle's recent marketing materials are, I'm pretty sure they don't have an HR app that can be load-balanced on the app layer in alongside an expense app and an ERP app. Maybe in another 10 years. Then again, I have started to see business suites where they host the whole thing for you, and this could be a model for their underlying infrastructure.ggathagan - Tuesday, April 28, 2015 - link
In the original article on these servers, it was stated that the PSU's were run on 277v, as opposed to 208v.277v involves three phase power wiring, which is common in commercial buildings, but usually restricted to HVAC-related equipment and lighting.
That article stated that Facebook saved "about 3-4% of energy use, a result of lower power losses in the transmission lines."
If the OpenRack carries that design over, companies will have to add the cost of bringing power 277v to the rack in order to realize that gain in efficiency.
sor - Wednesday, April 29, 2015 - link
208 is 3 phase as well, generally 3x120v phases, with 208 tapping between phases or 120 available to neutral. Its very common for DC equipment. 277 to the rack IS less common, but you seemed to get hung up on the 3 phase part.Casper42 - Monday, May 4, 2015 - link
3 phase restricted to HVAC?Thats ridiculous, I see 3 Phase in DataCenters all the time.
And Server vendors are now selling 277vAC PSUs for exactly this reason that FB mentions. Instead of converting the 480v main to 220 or 208, you just take a 277 feed right off the 3 phase and use it.
clehene - Tuesday, April 28, 2015 - link
You mention a reported $2 Billion in savings, but the article you refer to states $1.2 Billion.FlushedBubblyJock - Tuesday, April 28, 2015 - link
One is the truth and the other is "NON Generally Accepted Accounting Procedures" aka it's lying equivalent.wannes - Wednesday, April 29, 2015 - link
Link corrected. Thanks!