The Next Generation Open Compute Hardware: Tried and Tested
by Johan De Gelas & Wannes De Smet on April 28, 2015 12:00 PM ESTNetworking
Server contributions aren't the only things happening under the Open Compute project. Over the last couple of years a new focus on networking was added. Accton, Alpha Networks, Broadcom, Mellanox and Intel have each released a draft specification of a bare-metal switch to the OCP networking group. The premise of standardized bare-metal switches is simple: you can source standard switch models from multiple vendors, and run the OS of your choosing on it, along with your own management tools like Puppet. No lock-in and almost no migration path to be concerned with when implementing different equipment.
To that end, Facebook created Wedge, a 40G QSFP+ ToR switch together with the Linux-based FBOSS switch operating system to spur development in the switching industry, and, as always, to offer a better value for the price. FBOSS (along with Wedge) was recently open sourced, and in the process accomplished something far bigger: convincing Broadcom to release OpenNSL, an open SDK for their Trident II switching ASIC. Wedge's main purpose is to decrease vendor dependency (e.g. choose between an Intel or ARM CPU, choice of switching silicon) and allow consistency across part vendors. FBOSS lets the switch be managed with Facebook's standard fleet management tools. And it's not Facebook alone who can play with Wedge anymore, as Accton announced it will bring a Wedge based switch to market.

Facebook Wedge in all its glory
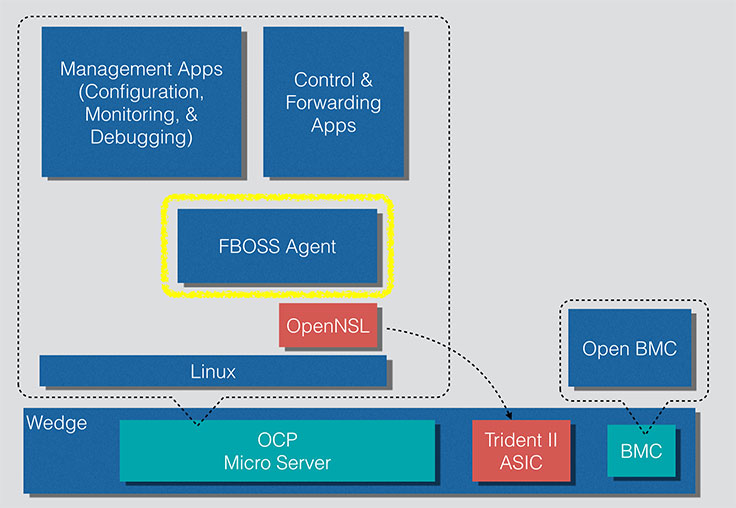
Logical structure of the Wedge software stack
But in Facebook's leaf-spine network design, you need some heavier core switches as well, connecting all the individual ToR switches to build the datacenter fabric. Traditionally those high-capacity switches are sold by the big network gear vendors like Cisco and Juniper, and at no small cost. You might then be able to guess what happens next: a few days ago Facebook launched '6-pack', its modular, high-capacity switch.

Facebook 6-pack, with 2 groups of line/fabric cards
A '6-pack' switch consists of two module types: line cards and fabric cards. A line card is not so different from a Wegde ToR switch, where 16 40GbE QSFP+ ports at the front are supplied with 640Gbps of the 1.2Tbps ASIC's switching capacity; the main difference with Wedge is the remaining 640Gbps is linked to a new backside Ethernet-based interconnect, all in a smaller form factor. The line card also has a Panther micro server with BMC for ASIC management. In the chassis, there are two rows of two line cards in one group, each operating independently of the other.

Line card (note the debug header pins left to the QSFP+ ports)
The fabric card is the bit connecting all of the line cards together, and thus the center part of the fabric. Though the fabric switch appears to be one module, it actually contains two switches (two 1.2Tbps packet crunchers, each paired to a Panther microcontroller), and like the line cards, they operate separate from each other. The only thing being shared is the management networking path, used by the Panthers and their BMCs, along with the management ports for each of the line cards.

Fabric card, with management ports and debug headers for the Panther cards
With these systems, Facebook has come a long way towards making its entire datacenter networking built with open, commodity components and running it using open software. The networking vendors are likely to notice these developments, and not only because of their pretty blue color.
ONIE
An effort to increase modularity even more is ONIE, short for the Open Network Install Environment. ONIE is focused on eliminating operating system lock-in by providing an environment for installing common operating systems like CentOS and Ubuntu on your switching equipment. ONIE is baked into the switch firmware, and after installation the onboard bootloader (GRUB) directly boots the OS. But before you start writing your Puppet or Chef recipes to manage your switches, a small but important side-note needs to be added: to operate the switching silicon of the Trident ASIC you need a proprietary firmware blob from Broadcom. And up until very recently, Broadcom would not give you the firmware blob unless you have some kind of agreement with them. This is why, currently, the only OSs you can install on ONIE enabled switches are commercial OSes like BigSwitch and Cumulus, who have agreements in place with the silicon vendors.
Luckily, Microsoft, Dell, Facebook, Broadcom, Intel and Mellanox have started work on a Switch Abstraction Interface (proposals), which would obviate the need for any custom firmware blobs and allow standard cross-vendor compatibility, though it remains to be seen to which degree this can completely replace proprietary firmware.








26 Comments
View All Comments
Kevin G - Tuesday, April 28, 2015 - link
Excellent article.The efficiency gains are apparent even using suboptimal PSU for benchmarking. (Though there are repeated concurrency values in the benchmarking tables. Is this intentional?)
I'm looking forward to seeing a more compute node hardware based around Xeon-D, ARM and potentially even POWER8 if we're lucky. Options are never a bad thing.
Kind of odd to see the Knox mass storage units, I would have thought that OCP storage would have gone the BackBlaze route with vertically mount disks for easier hot swap, density and cooling. All they'd need to develop would have been a proprietary backplane to handle the Kinetic disks from Seagate. Basic switching logic could also be put on the backplane so the only external networking would be high speed uplinks (40 Gbit QSFP+?).
Speaking of the Kinetic disks, how is redundancy handled with a network facing drive? Does it get replicated by the host generating the data to multiple network disks for a virtual RAID1 redundancy? Is there an aggregator that handles data replication, scrubbing, drive restoration and distribution, sort of like a poor man's SAN controller? Also do the Kinetic drives have two Ethernet interfaces to emulate multi-pathing in the event of a switch failure (quick Googling didn't give me an answer either way)?
The cold storage racks using Blu-ray discs in cartridges doesn't surprise me for archiving. The issue I'm puzzled with is the process how data gets moved to them. I've been under the impression that there was never enough write throughput to make migration meaningful. For a hypothetical example, by the time 20 TB of data has been written to the discs, over 20 TB has been generated that'd be added to the write queue. Essentially big data was too big to archive to disc or tape. Parallelism here would solve the throughput problem but that get expensive and takes more space in the data center that could be used for hot storage and compute.
Do the Knox storage and Wedge networking hardware use the same PDU connectivity as the compute units?
Are the 600 mm wide racks compatible use US Telecom rack width equipment (23" wide)? A few large OEMs offer equipment in that form factor and it'd be nice for a smaller company to mix and match hardware with OCP to suit their needs.
nils_ - Wednesday, April 29, 2015 - link
You can use something like Ceph or HDFS for data redundancy which is kind of like RAID over network.davegraham - Tuesday, April 28, 2015 - link
Also, Juniper Networks has an ONIE-compliant OCP switch called the OCX1100 which is the only Tier1 switch manufacturer (e.g. Cisco, Arista, Brocade) to provide such a device.floobit - Tuesday, April 28, 2015 - link
This is very nice work. One of the best articles I've seen here all year. I think this points at the future state of server computing, but I really wonder if the more traditional datacenter model (VMware on beefy blades with a proprietary FC-connected SAN) can be integrated with this massively-distributed webapp model. Load-balancing and failovering is presumably done in the app layer, removing the need for hypervisors. As pretty as Oracle's recent marketing materials are, I'm pretty sure they don't have an HR app that can be load-balanced on the app layer in alongside an expense app and an ERP app. Maybe in another 10 years. Then again, I have started to see business suites where they host the whole thing for you, and this could be a model for their underlying infrastructure.ggathagan - Tuesday, April 28, 2015 - link
In the original article on these servers, it was stated that the PSU's were run on 277v, as opposed to 208v.277v involves three phase power wiring, which is common in commercial buildings, but usually restricted to HVAC-related equipment and lighting.
That article stated that Facebook saved "about 3-4% of energy use, a result of lower power losses in the transmission lines."
If the OpenRack carries that design over, companies will have to add the cost of bringing power 277v to the rack in order to realize that gain in efficiency.
sor - Wednesday, April 29, 2015 - link
208 is 3 phase as well, generally 3x120v phases, with 208 tapping between phases or 120 available to neutral. Its very common for DC equipment. 277 to the rack IS less common, but you seemed to get hung up on the 3 phase part.Casper42 - Monday, May 4, 2015 - link
3 phase restricted to HVAC?Thats ridiculous, I see 3 Phase in DataCenters all the time.
And Server vendors are now selling 277vAC PSUs for exactly this reason that FB mentions. Instead of converting the 480v main to 220 or 208, you just take a 277 feed right off the 3 phase and use it.
clehene - Tuesday, April 28, 2015 - link
You mention a reported $2 Billion in savings, but the article you refer to states $1.2 Billion.FlushedBubblyJock - Tuesday, April 28, 2015 - link
One is the truth and the other is "NON Generally Accepted Accounting Procedures" aka it's lying equivalent.wannes - Wednesday, April 29, 2015 - link
Link corrected. Thanks!