Intel Executive Posts Thunderbolt 5 Photo then Deletes It: 80 Gbps and PAM-3
by Dr. Ian Cutress on August 1, 2021 1:29 PM EST
An executive visiting various research divisions across the globe isn’t necessarily new, but with a focus on social media driving named individuals at each company to keep their followers sitting on the edge of their seats means that we get a lot more insights into how these companies operate. The downside of posting to social media is when certain images exposing unreleased information are not vetted by PR or legal, and we get a glimpse into the next generation of technology. That is what happened today.
Day 1 with the @intel Israel team in the books. Great views…incredible opp to see @GetThunderbolt innovation …a validation lab tour and time with the team…can’t wait to see what tomorrow brings! pic.twitter.com/GKOddA6TNi
— Gregory M Bryant (@gregorymbryant) August 1, 2021
EVP and GM of Intel’s Client Computing Group, Gregory Bryant, is this week spending some time at Intel’s Israel R&D facilities in his first overseas Intel trip in of 2021. An early post on Sunday morning, showcasing Bryant’s trip to the gym to overcome jetlag, was followed by another later in the day with Bryant being shown the offices and the research. The post contained four photos, but was rapidly deleted and replaced by a photo with three (in the tweet above). The photo removed showcases some new information about next-generation Thunderbolt technology.

In this image we can see a poster on the wall showcasing ‘80G PHY Technology’, which means that Intel is working on a physical layer (PHY) for 80 Gbps connections. Off the bat this is double the bandwidth of Thunderbolt 4, which runs at 40 Gbps.
The second line confirms that this is ‘USB 80G is targeted to support the existing USB-C ecosystem’, which follows along that Intel is aiming to maintain the USB-C connector but double the effective bandwidth.
The third line is actually where it gets technically interesting. ‘The PHY will be based on novel PAM-3 modulation technology’. This is talking about how the 0 and 1s are transmitted – traditionally we talk about NRZ encoding, which just allows for a 0 or a 1 to be transmitted, or a single bit. The natural progression is a scheme allowing two bits to be transferred, and this is called PAM-4 (Pulse Amplitude Modulation), with the 4 being the demarcation for how many different variants two bits could be seen (either as 00, 01, 10, or 11). PAM-4, at the same frequency, thus has 2x the bandwidth of an NRZ connection.
So what on earth in PAM-3?
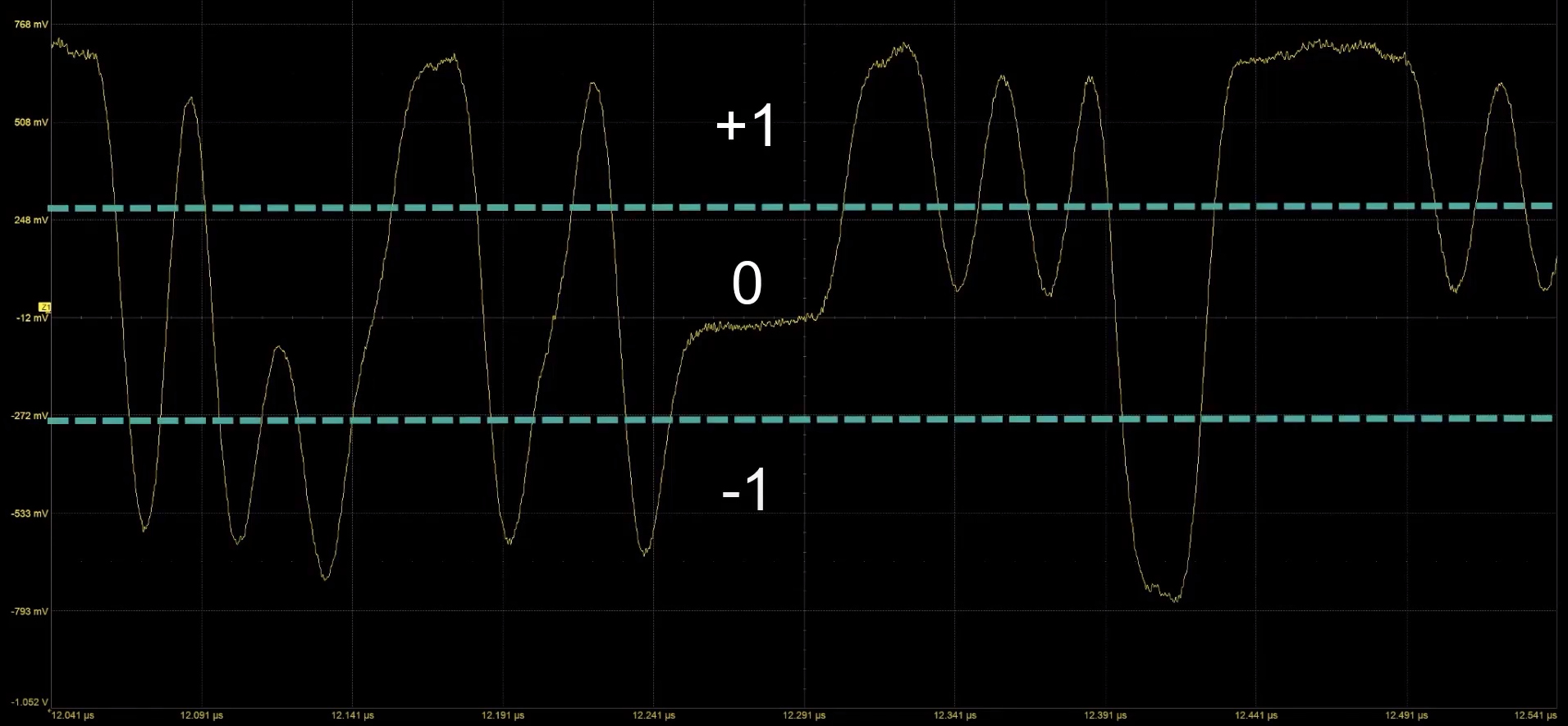
From Teledyne LeCroy on YouTube
PAM-3 is a technology where the data line can carry either a -1, a 0, or a +1. What the system does is actually combine two PAM-3 transmits into a 3-bit data signal, such as 000 is an -1 followed by a -1. This gets complex, so here is a table:
| PAM-3 Encoding | ||
| AnandTech | Transmit 1 |
Transmit 2 |
| 000 | -1 | -1 |
| 001 | -1 | 0 |
| 010 | -1 | 1 |
| 011 | 0 | -1 |
| 100 | 0 | 1 |
| 101 | 1 | -1 |
| 110 | 1 | 0 |
| 111 | 1 | 1 |
| Unused | 0 | 0 |
When we compare NRZ to PAM-3 and PAM-4, we can see the rate of data transfer for PAM-3 is in the middle of NRZ and PAM-4. The reason why PAM-3 is being used in this case is to achieve that higher bandwidth without the extra limitations that PAM-4 requires to be enabled.
| NRZ vs PAM-3 vs PAM4 | |||
| AnandTech | Bits | Cycles | Bits Per Cycle |
| NRZ | 1 | 1 | 1 |
| PAM-3 | 3 | 2 | 1.5 |
| PAM-4 | 2 | 1 | 2 |
PAM-3 has similar limitations to NRZ.
The final line on this image is ‘[something] N6 test-chip focusing on the new PHY technology is working in [the lab and] showing promising results’. That first word I thought was TSMC, but it has to be about the same width as the ‘The’ on the line above. So it doesn’t look like I’m right there, but N6 is a TSMC node.
Intel’s goal with Thunderbolt is going to be both driving bandwidth, power, and utility, but also right now it seems keeping it to the USB-C standard is going to be a vital part of keeping the technology useful for users who can fall back on standard USB-C connections. Right now Intel’s TB4 is a superset that includes USB4, so we might see another situation where TB5 is ready to be a superset of USB5 as well, however it seems that USB standards are slower to roll out than TB standards right now.
Special thanks to David Schor from WikiChip for the tipoff.
Related Reading
- Intel's CES 2021 Press Event: The Future of Intel (A Live Blog, 1pm PT)
- Intel Launches 11th Gen Core Tiger Lake: Up to 4.8 GHz at 50 W, 2x GPU with Xe, New Branding
- Intel Thunderbolt 4 Update: Controllers and Tiger Lake in 2020
- Intel’s 11th Gen Core Tiger Lake SoC Detailed: SuperFin, Willow Cove and Xe-LP
- DisplayPort Alt Mode 2.0 Spec Released: Defining Alt Mode for USB4
- Cypress Announces USB 3.2 & USB4-Ready Controllers: EZ-PD CCG6DF & CCG6SF
- USB 3.2 Gen 2x2 State of the Ecosystem Review: Where Does 20Gbps USB Stand in 2020?








82 Comments
View All Comments
mode_13h - Wednesday, August 4, 2021 - link
I can't speak to the feasibility of that, on an electrical level, though I wonder if various memory cells are equally adept at storing charges of either polarity.I've heard of ternary logic. I've even used 3-state variables in some code, going so far as to implement a full contingent of ternary logic operators. With that said, I would absolutely *hate* for computers to use 3-state bits. Binary simplifies soooo many things, in computing.
Even if you implemented it and got real efficiency gains, there's like 50+ years' worth of software written with the assumption that binary operations are cheap. And the overhead of emulating binary on ternary logic would waste a lot of whatever you could hope to gain, in terms of base efficiency.
Kangal - Friday, August 6, 2021 - link
Yes, that's exactly what I'm talking about.Building a brand-new computing mechanism using "trits" instead of "bits". And here's the kicker, this additional complexity will exponentially increase efficiency and performance. So emulating traditional Binary Computing can be done via software.
And to demonstrate this concept, just think about DNA. It uses 4-digits (nucleotides) which is converted to amino acids, while there's quiet a few combinations, we only see 20 of them. And these blocks then make EVERY protein in the world. Just think about all the variations, from plants, minerals, microbes, animal cells, even spider's silk! So going from 2-bits to 3-bits is NOT a mere increase of +50%, but a stupidly higher order of complexity, especially when you combine it with a "tryte". So reading batches of trits/bits, for instance, a relatively simple 3^27 is about as complex as a computationally hard 2^64 (ie 64-bit instruction set). Or the "equivalent 64" for 2-bits when based on 3-powers is "81-trit".... and that 3^81 is complex is cryptographically stronger than 2^128 (a la 128-bit). So, yeah.
As far as legacy code is concerned, who cares. Sometimes you have to burn the bush before you can grow forest. Case in point, moving from the "Apple III" to the "Macintosh" then to "Intel Mac" then phasing to "64bit Mac" and now "ARM Macs". That's 4-6 major architectural leaps over a 40-year period, or roughly, an update every SIX-to-TEN years.
For the initial six years, or first-gen, a lot of the binary development code could be recycled. For instance, the iOS SDK can be quick-written for trits/trytes. And this will give a decent boost in efficiency and performance. But after a decade, when it enters the maturation stage or second-gen, that's when (for instance) the iOS SDK will be completely re-written from the ground up. And that would be using the hardware closer to its potential, giving a huge boost in both efficiency and performance. After that comes the plateau phase where novel techniques become discovered, and small victories in hardware and software, they eventually add up to further big boost.
...so yeah, that's where my head is at!
mode_13h - Saturday, August 7, 2021 - link
> this additional complexity will exponentially increase efficiency and performance.Please justify this assertion. Not by analogy, either. Use maths.
> And to demonstrate this concept, just think about DNA. It uses 4-digits (nucleotides)
There are 4 bases, but they're organized in complementary pairs. That means there are only 2 base-pairs, but since I think the polarity is significant, you get 4 states. By my count, that makes it equivalent to a 2-bit quantity.
> these blocks then make EVERY protein in the world.
Binary bits represent ALL digital information in the world! What's your point?
> So going from 2-bits to 3-bits
You didn't propose 3 bits, you proposed 3 states. That equates to 1.5 bits. Consider that the number of combinations representable with 5 tri-state bits is 3^5 = 243. In binary, that takes the better part of 8 bits (2^8 = 256). So, your increase of information density is only 60% (if we disregard the extra 13 values 2^8 can represent).
Now, aside from information density, there are further considerations. I already mentioned the electrical characteristics of the storage cells being one unknown, but the other is the complexity of logic gates needed to implement tri-state logic. We don't know how much larger or more complex they'd be. Finally, I'd worry that the amount of time needed for the signal to reliably settle into one of these states is longer or would require a higher voltage, both of which run contrary to performance scaling.
> As far as legacy code is concerned, who cares.
That's easy for you to say. Just to cite one example, the cost of writing something equivalent to the Linux kernel would run well into the $Billions. I don't want to get side-tracked on debating the merits of one source vs. another, but you can do your own search and I think you'll find data consistent with that. I pick on operating systems, since they're most sensitive to the differences between binary & 3-state, but that's not to say there's not a vast amount of userspace also impacted.
> Case in point
No, they're not. The closest examples would be their move from PowerPC to Intel, and then from Intel to ARM. Those are the only cases involving a truly modern OS. However, they didn't have to do a ground-up rewrite. All they had to do was port the stuff tied to the low-level CPU architecture, which tends to be somewhat compartmentalized and abstracted, in modern operating systems. Probably 95% of the OS code could simply be recompiled for the new ISA.
What you're talking about is much more fundamental. If you look at everywhere OS and device driver code relies on a binary representation, it'd be a staggering amount. I'd guess probably on the order of 50% of the code would be affected. And adjusting it to work in 3-state logic could be non-trivial, in many cases.
The last point I have to offer is that tri-state logic is hardly new. It has specialized applications, meaning there are people very familiar with it. If it made sense to use more broadly, I'd expect that would've already happened.
https://en.wikipedia.org/wiki/Three-state_logic
callum.wright - Friday, August 6, 2021 - link
Ever heard of the Dunning–Kruger effect mate? Because you're living itmode_13h - Saturday, August 7, 2021 - link
Well, yeah. But it's more fun & instructive to dismantle an ill conceived argument than simply attacking its proponent. We were all noobs at some point. At best, errors and mistakes represent learning opportunities.The_Assimilator - Sunday, August 1, 2021 - link
"The reason why PAM-3 is being used in this case is to achieve that higher bandwidth without the extra limitations that PAM-4 requires to be enabled."Limitations such as...?
And this is quite honestly bizarre, why would Intel have a slide deck for something that's nowhere near release yet? Why would they have a printout of said slide stuck on their wall... do their own TB techs not know what they're working on?
Ian Cutress - Sunday, August 1, 2021 - link
Executive doing a whirlwind tour, being shown the new technology, and each segment is being presented.zdz - Sunday, August 1, 2021 - link
Each higher order modulation type require more signal-to-noise ratio, to discern between signal levels. This means with higher modulation you need "better" cables, which are either thicker (unwieldy) or made of purer metals (more expensive).Yojimbo - Sunday, August 1, 2021 - link
Or you have shorter maximum cable lengths...eastcoast_pete - Sunday, August 1, 2021 - link
Good question: just how short are we talking about? Some of the "recommended lengths" seem to approach the size of a USB connector, so best given in mm, not cm or Inches.