Dissecting Intel's EPYC Benchmarks: Performance Through the Lens of Competitive Analysis
by Johan De Gelas & Ian Cutress on November 28, 2017 9:00 AM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Skylake-SP
- Xeon Platinum
- EPYC
- EPYC 7601
Enterprise & Cloud Benchmarks
Below you can find Intel's internal benchmarking numbers. The EPYC 7601 is the reference (performance=1), the 8160 is represented by the light blue bars, the top of the line 8180 numbers are dark blue. On a performance per dollar metric, it is the light blue worth observing.
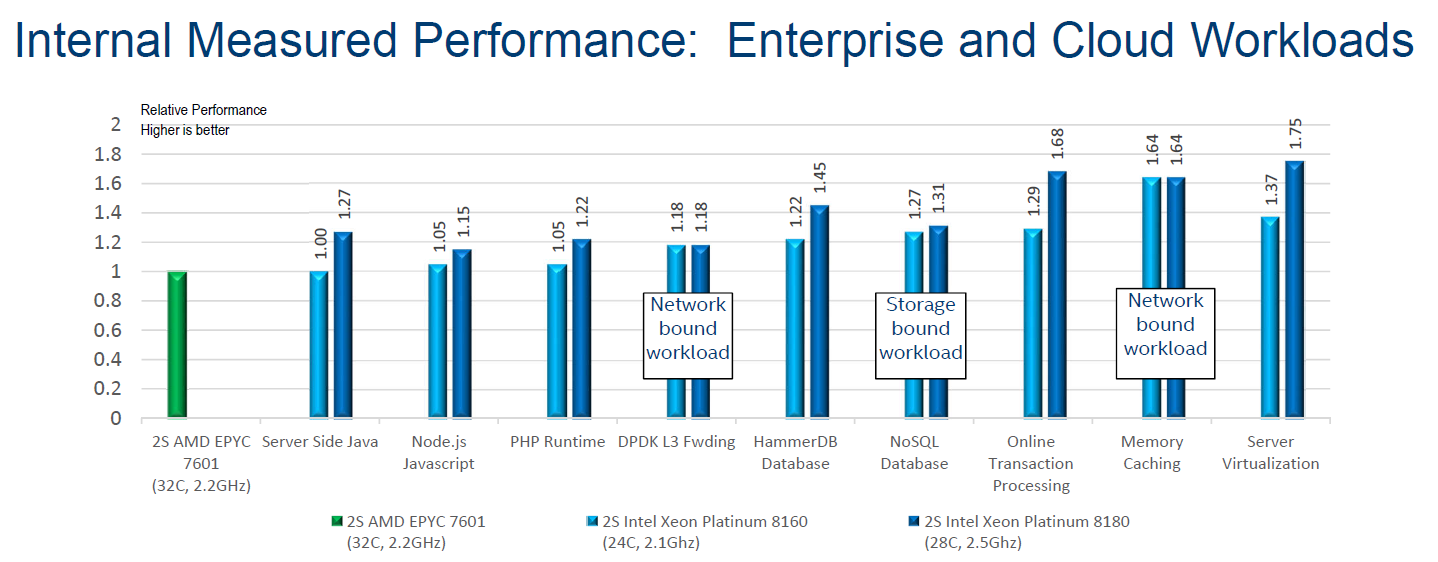
Java benchmarks are typically unrealistically tuned, so it is a sign on the wall when an experienced benchmark team is not capable to make the Intel 8160 shine: it is highly likely that the AMD 7601 is faster in real life.
The node.js and PHP runtime benchmarks are very different. Both are open source server frameworks to generate for example dynamic page content. Intel uses a client load generator to generate a real workload. In the case of the PHP runtime, MariaDB (MySQL derivative) 10.2.8 is the backend.
In the case of Node.js, mongo db is the database. A node.js server spawns many different single threaded processes, which is rather ideal for the AMD EPYC processor: all data is kept close to a certain core. These benchmarks are much harder to skew towards a certain CPU family. In fact, Intel's benchmarks seem to indicate that the AMD EPYC processors are pretty interesting alternatives. Surely if Intel can only show a 5% advantage with a 10% more expensive processor, chances are that they perform very much alike in the real world. In that case, AMD has a small but tangible performance per dollar advantage.
The DPDK layer 3 Network Packet Forwarding is what most of us know as routing IP packets. This benchmark is based upon Intel own Data Plane Developer Kit, so it is not a valid benchmark to use for an AMD/Intel comparison.
We'll discuss the database HammerDB, NoSQL and Transaction Processing workloads in a moment.
The second largest performance advantage has been recorded by Intel testing the distributed object caching layer memcached. As Intel notes, the benchmark was not a processing-intensive workload, but rather a network-bound workload. As AMD's dual socket system is seen as a virtual 8-socket system, due to the way that AMD has put four dies onto each processor and each die has a sub-set of PCIe lanes linked to it, AMD is likely at a disadvantage.
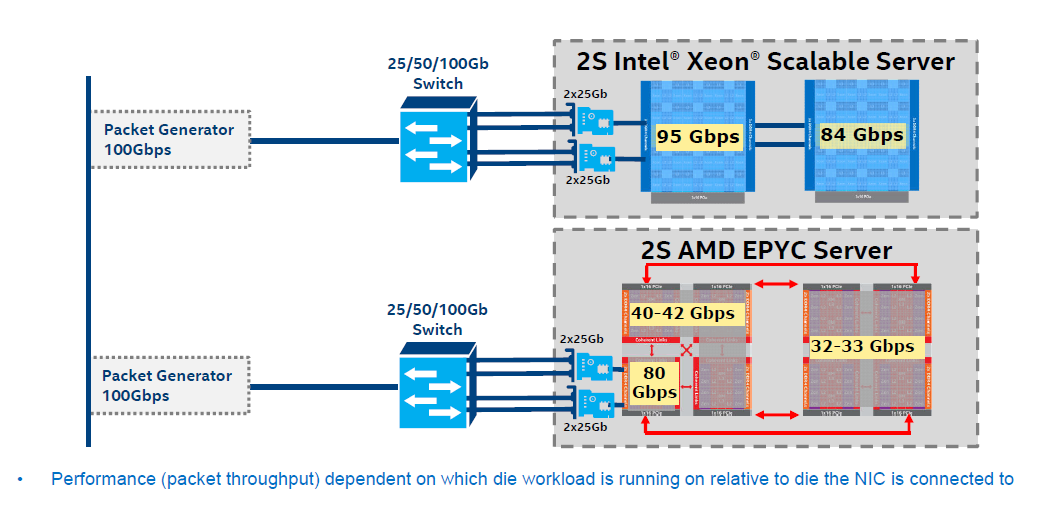
Intel's example of network bandwidth limitations in a pseudo-socket configuration
Suppose you have two NICs, which is very common. The data of the first NIC will, for example, arrive in NUMA node 1, Socket 1, only to be accessed by NUMA node 4, Socket 1. As a result, there is some additional latency incurred. In Intel's case, you can redirect a NIC to each socket. With AMD, this has to be locally programmed, to ensure that the packets that are sent to each NICs are processed on each virtual node, although this might incur additional slowdown.
The real question is whether you should bother to use a 2S system for Memached. After all, it is distributed cache layer that scales well over many nodes, so we would prefer a more compact 1S system anyway. In fact, AMD might have an advantage as in the real world, Memcached systems are more about RAM capacity than network or CPU bottlenecks. Missing the additional RAM-as-cache is much more dramatic than waiting a bit longer for a cache hit from another server.
The virtualization benchmark is the most impressive for the Intel CPUs: the 8160 shows a 37% performance improvement. We are willing to believe that all the virtualization improvements have found their way inside the ESXi kernel and that Intel's Xeon can deliver more performance. However, in most cases, most virtualization systems run out of DRAM before they run out of CPU processing power. The benchmarking scenario also has a big question mark, as in the footnotes to the slides Intel achieved this victory by placing 58 VMs on the Xeon 8160 setup versus 42 VMs on the EPYC 7601 setup. This is a highly odd approach to this benchmark.
Of course, the fact that the EPYC CPU has no track record is a disadvantage in the more conservative (VMware based) virtualization world anyway.








105 Comments
View All Comments
beginner99 - Tuesday, November 28, 2017 - link
CPU price or server price are almost always irrelevant because the software running on them costs at least an order of magnitude more than the hardware itself. So you get the fastest server you need / the software profits from.ddriver - Tuesday, November 28, 2017 - link
Not necessarily, there is a lot of free and opensource software that is enterprise-capable.Also "the fastest server" actually sell in very small quantities. Clearly the cpu cost is not irrelevant as you claim. And clearly if it was irrelevant, intel would not even bother offering low price skus, which actually constitute the bulk of it sales, in terms of quantity as well as revenue.
yomamafor1 - Tuesday, November 28, 2017 - link
128GB for 32 core is suspiciously low.... For that kind of core count, generally the server has 512GB or above.Also, 128GB of memory in this day and age is definitely not $1,500 tops. Maybe in early 2016, but definitely not this year, and definitely not next year.
And from what I've seen, the two biggest cost factors in an enterprise grade server is the SSDs and memory. Generally memory accounts for 20% of the server cost, while SSD accounts for about 30%.
CPU generally accounts for 10% of the cost. Not insignificant, but definitely not "makes up half of the machine's budget".
AMD has a very hard battle to get back into the datacenter. Intel is already competing aggressively.
ddriver - Tuesday, November 28, 2017 - link
Care to share with us your "correct ram amount per cpu core" formula? There I was, thinking that the amount of ram necessary was determined by the use case, turns out it is a product of core count.bcronce - Tuesday, November 28, 2017 - link
In general a server running VMs is memory limited well before CPU limited.ddriver - Tuesday, November 28, 2017 - link
Not necessarily. It depends on what kind of work will those VMs be doing. Visualized or bare metal, configuration details are dictated by the target use case. Sure, you can also build universal machines and cram them full of as much cores and memory they can take, but that is very cost ineffective.I can think of a usage scenario that will be most balanced with a quad core cpu and 1 terabyte of ram. Lots of data, close to no computation taking place, just data reads and writes. A big in-memory database server.
I can think of a usage scenario that will be most balanced with a 32 core cpu and 64 gigabytes of ram. An average sized data set involved in heavy computation. A render farm node server.
ddriver - Tuesday, November 28, 2017 - link
*virtualized not visualized LOL, did way too many visualizations back in the day, hands now type on autopilot...yomamafor1 - Tuesday, November 28, 2017 - link
It is certainly determined by the use cases, but after interacting with hundreds of companies and their respective workloads, generally higher core counts are mapped to higher memory capacity.Of course, there are always very few fringe use cases that focuses significantly on compute.
Holliday75 - Saturday, December 9, 2017 - link
What about large players like Microsoft Azure or AWS? I have worked with both and neither uses anything close to what you guys talk about in terms of RAM or CPU. Its all about getting the most performance per watt. When you data center has its own substation your electric bill might be kinda high.submux - Thursday, November 30, 2017 - link
I will overlook the rudeness of your comment. I actively work with enterprise hardware and would probably not make comments like that and then recommend outfitting a server with 128GB of RAM. I don't think I've been near anything with as little as that in a long while. 128GB is circa 2012-2013.An enterprise needs 6 servers to ensure one operational node in a redundant environment. This is because in two data centers, you have 3 servers each. In case of a catastrophe, a full data center is lost and while a server is in maintenance and then finally another server fails. Therefore, you need precisely 6 servers to provide a reasonable SLA. 9 servers is technically more correct, in a proper 3 data center design.
If you know anything about storage, you would prefer more servers as more servers provides better storage response times... unless you're using SAN which is pretty much reserved strictly to people who simply don't understand storage and are willing to forfeit price, performance, reliability, stability, etc... to avoid actually taking a computer science education.
In enterprise IT, there are many things to consider. But for your virtualization platform, it's pretty simple. Fit as much capacity as possible in to as few U as possible while never dropping below 6 servers. Of course, I rarely work with less than 500 servers at a time, but I focus on taking messy 10,000+ server environments and shrinking them to 500 or less.
See, each server you add adds cost to operation. This means man-hours. Storage costs. Degradation of performance in the fabrics, etc... it introduces meaningless complexity and requires IT engineers to waste more and more hours building illogical platforms more focused on technology than the business they were implemented for.
If I approach a customer, I tend to let them know that unless they are prepared to invest at least $50,000 per server for 6 servers and $140,000 for the appropriate network, they should deploy using an IaaS solution (not cloud, never call IaaS cloud) where they can share a platform that was built to these requirements. The breaking point where IaaS is less economical than DIY is at about $500,000 with an OpEx investment of $400,000-$600,000 for power, connectivity, human resources, etc... annually and this doesn't even include having experts on the platform running on the data center itself.
So with less than a minimum of $1 million a year investment in just providing infrastructure (VMware, Nutanix, KVM, Hyper-V), not even providing a platform to run on it, you're just pissing the wrong way in the wind tunnel and wasting obscene amounts of money for no apparent reason on dead-end projects run by people who spend money without considering the value provided.
In addition, the people running your data center for that price are increasing in cost and their skillset is aging and decreasing in value over that time.
I haven't even mentioned power, cooling, rack space, cabling, managed PDUs, electricians, plumbers, fire control, etc...
Unless you're working with BIG DATA, an array of 2-4 TB drives for under $10,000 to feed even one 32-core AMD EPYC is such an insanely bad idea, it's borderline criminal stupidity. Let's not even discuss feeding pipelines of 6 32-core current generation CPUs per data center. It would be like trying to feed a blue whale with a teaspoon. In a virtualized configuration a deal EPYC server probably would need 100GB/s+ bandwidth to barely keep ahead of process starvation.
If you have any interest at all in return on investment in enterprise IT, you really need to up your game to make it work on paper.
Now... consider that if you're running a virtual data center... plain vanilla. Retail license cost of Windows Enterprise and VMware (vCenter, NSX, vSAN) for a dual 32-core EPYC is approximately $125,000 a server. Cutting back to dual 24-core with approximately the same performance would save about $30,000 a server in software alone.
I suppose I can go on and on... but let's be pretty clear CajunArson made a fair comment and probably is considering the cost of 1-2TB per server of RAM. Not 128GB which is more of a graphics workstation in 2017.