The AMD Ryzen Threadripper 1950X and 1920X Review: CPUs on Steroids
by Ian Cutress on August 10, 2017 9:00 AM ESTCPU Rendering Tests
Rendering tests are a long-time favorite of reviewers and benchmarkers, as the code used by rendering packages is usually highly optimized to squeeze every little bit of performance out. Sometimes rendering programs end up being heavily memory dependent as well - when you have that many threads flying about with a ton of data, having low latency memory can be key to everything. Here we take a few of the usual rendering packages under Windows 10, as well as a few new interesting benchmarks.
All of our benchmark results can also be found in our benchmark engine, Bench.
Corona 1.3: link
Corona is a standalone package designed to assist software like 3ds Max and Maya with photorealism via ray tracing. It's simple - shoot rays, get pixels. OK, it's more complicated than that, but the benchmark renders a fixed scene six times and offers results in terms of time and rays per second. The official benchmark tables list user submitted results in terms of time, however I feel rays per second is a better metric (in general, scores where higher is better seem to be easier to explain anyway). Corona likes to pile on the threads, so the results end up being very staggered based on thread count.
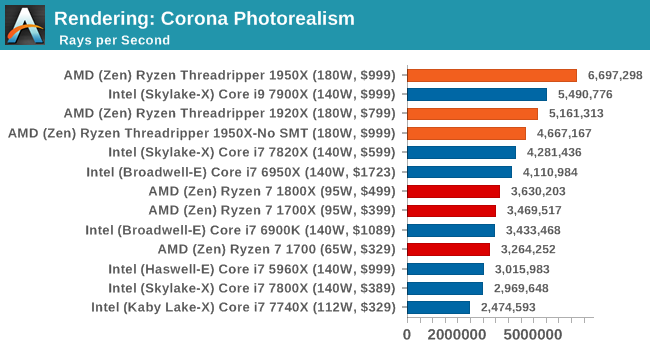
Corona loves threads.
Blender 2.78: link
For a render that has been around for what seems like ages, Blender is still a highly popular tool. We managed to wrap up a standard workload into the February 5 nightly build of Blender and measure the time it takes to render the first frame of the scene. Being one of the bigger open source tools out there, it means both AMD and Intel work actively to help improve the codebase, for better or for worse on their own/each other's microarchitecture.
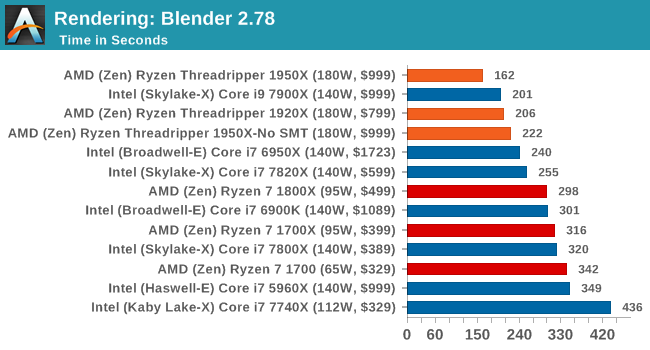
Blender loves threads and memory bandwidth.
LuxMark v3.1: Link
As a synthetic, LuxMark might come across as somewhat arbitrary as a renderer, given that it's mainly used to test GPUs, but it does offer both an OpenCL and a standard C++ mode. In this instance, aside from seeing the comparison in each coding mode for cores and IPC, we also get to see the difference in performance moving from a C++ based code-stack to an OpenCL one with a CPU as the main host.

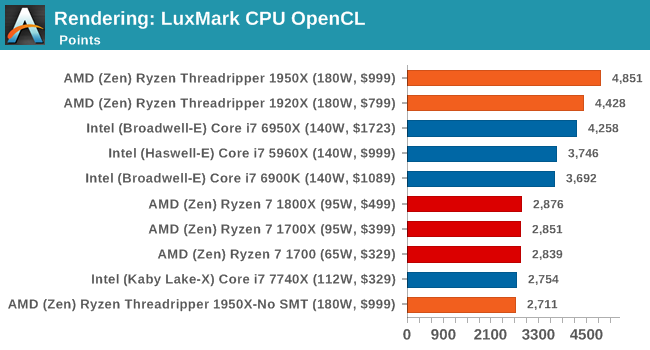
Like Blender, LuxMark is all about the thread count. Ray tracing is very nearly a textbook case for easy multi-threaded scaling. Though it's interesting just how close the 10-core Core i9-7900X gets in the CPU (C++) test despite a significant core count disadvantage, likely due to a combination of higher IPC and clockspeeds.
POV-Ray 3.7.1b4: link
Another regular benchmark in most suites, POV-Ray is another ray-tracer but has been around for many years. It just so happens that during the run up to AMD's Ryzen launch, the code base started to get active again with developers making changes to the code and pushing out updates. Our version and benchmarking started just before that was happening, but given time we will see where the POV-Ray code ends up and adjust in due course.
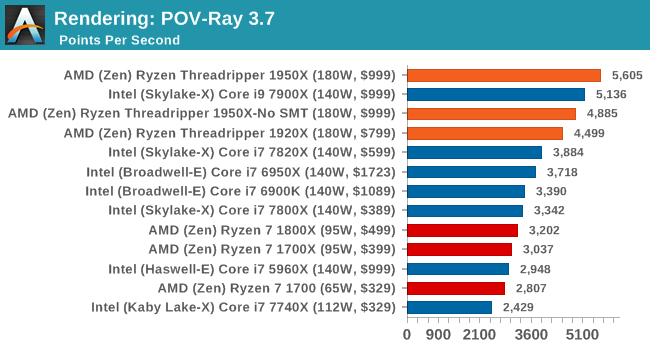
Similar to LuxMark, POV-Ray also wins on account of threads.
Cinebench R15: link
The latest version of CineBench has also become one of those 'used everywhere' benchmarks, particularly as an indicator of single thread performance. High IPC and high frequency gives performance in ST, whereas having good scaling and many cores is where the MT test wins out.
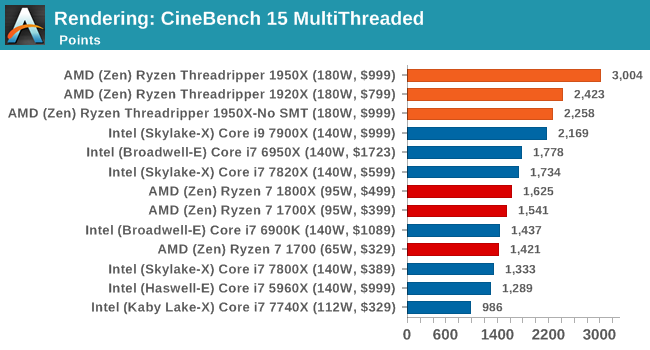
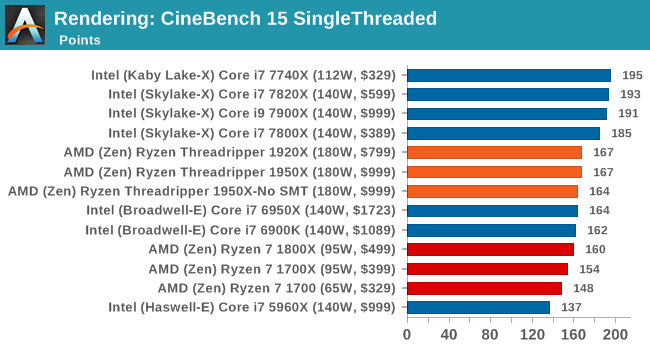
Intel recently announced that its new 18-core chip scores 3200 on Cinebench R15. That would be an extra 6.7% performance over the Threadripper 1950X for 2x the cost.








347 Comments
View All Comments
verl - Thursday, August 10, 2017 - link
"well above the Ryzen CPUs, and batching the 10C/8C parts from Broadwell-E and Haswell-E respectively"??? From the Power Consumption page.
bongey - Thursday, August 10, 2017 - link
Yep if you use AVX-512 it will down clock to 1.8Ghz and draw 400w just for the CPU alone and 600w from the wall. See der8auer's video title "The X299 VRM Disaster (en)", all x299 motherboards VRMs can be ran into thermal shutdown under avx 512 loads, with just a small overclock, not to mention avx512 crazy power consumption. That is why AMD didn't put avx 512 in Zen, it is power consumption monster.TidalWaveOne - Thursday, August 10, 2017 - link
Glad I went with the 7820X for software development (compiling).raddude9 - Thursday, August 10, 2017 - link
In ars' review they have TR-1950X ahead of the i9-7900X for compilation:https://arstechnica.co.uk/gadgets/2017/08/amd-thre...
In short it's very difficult to test compilation, every project you build has different properties.
emn13 - Thursday, August 10, 2017 - link
Yeah, the discrepency is huge - converted to anandtech's compile's per day the arstechnica benchmark maxes out at a little less than 20, which is a far cry from the we see here.Clearly, the details of the compiler, settings and codebase (and perhaps other things!) matter hugely.
That's unfortunate, because compilation is annoyingly slow, and it would be a boon to know what to buy to ameliorate that.
prisonerX - Thursday, August 10, 2017 - link
This is very compiler dependent. My compiler is blazingly fast on my wimpy hardware becuase it's blazingly clever. Most compilers seem to crawl no matter what they run on.bongey - Thursday, August 10, 2017 - link
Looks like anandtech's benchmark for compiling is bunk, it's just way off from all the other benchmarks out there. Not only that, no other test shows a 20% improvement over the 6950x which is also a 10 core/20 thread cpu. Something tells me the 7900x is completely wrong or has something faster like a different pcie ssd.Chad - Thursday, August 10, 2017 - link
All I know is, for those of us running Plex, SABnzbd, Sonarr, Radarr servers simultaneously (and others), while encoding and gaming all simultaneously, our day has arrived!:)
Ian Cutress - Thursday, August 10, 2017 - link
We checked with Ars as to their method.We use a fixed late March build around v56 under MSVC
Ars use a fixed newer build around v62 via clang-cl using VC++ linking
Same software, different compilers, different methods. Our results are faster than Ars, although Ars' results seem to scale better.
ddriver - Friday, August 11, 2017 - link
Of every review out there, only your "superior testing methodology" presents a picture where TR is slower than SX.