AMD Radeon R9 285 Review: Feat. Sapphire R9 285 Dual-X OC
by Ryan Smith on September 10, 2014 2:00 PM ESTTonga’s Microarchitecture - What We’re Calling GCN 1.2
As we alluded to in our introduction, Tonga brings with it the next revision of AMD’s GCN architecture. This is the second such revision to the architecture, the last revision (GCN 1.1) being rolled out in March of 2013 with the launch of the Bonaire based Radeon HD 7790. In the case of Bonaire AMD chose to kept the details of GCN 1.1 close to them, only finally going in-depth for the launch of the high-end Hawaii GPU later in the year. The launch of GCN 1.2 on the other hand is going to see AMD meeting enthusiasts half-way: we aren’t getting Hawaii level details on the architectural changes, but we are getting an itemized list of the new features (or at least features AMD is willing to talk about) along with a short description of what each feature does. Consequently Tonga may be a lateral product from a performance standpoint, but it is going to be very important to AMD’s future.
But before we begin, we do want to quickly remind everyone that the GCN 1.2 name, like GCN 1.1 before it, is unofficial. AMD does not publicly name these microarchitectures outside of development, preferring to instead treat the entire Radeon 200 series as relatively homogenous and calling out feature differences where it makes sense. In lieu of an official name and based on the iterative nature of these enhancements, we’re going to use GCN 1.2 to summarize the feature set.
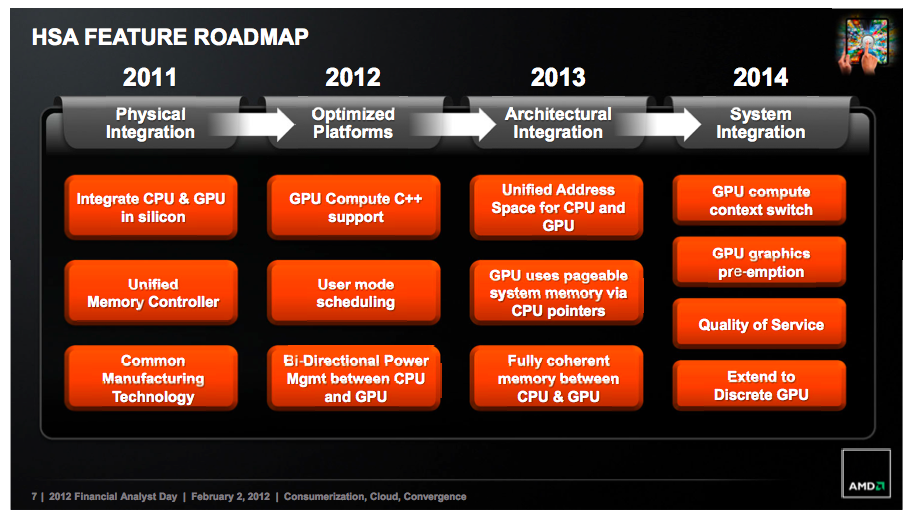
AMD's 2012 APU Feature Roadmap. AKA: A Brief Guide To GCN
To kick things off we’ll pull old this old chestnut one last time: AMD’s HSA feature roadmap from their 2012 financial analysts’ day. Given HSA’s tight dependence on GPUs, this roadmap has offered a useful high level overview of some of the features each successive generation of AMD GPU architectures will bring with it, and with the launch of the GCN 1.2 architecture we have finally reached what we believe is the last step in AMD’s roadmap: System Integration.

It’s no surprise then that one of the first things we find on AMD’s list of features for the GCN 1.2 instruction set is “improved compute task scheduling”. One of AMD’s major goals for their post-Kavari APU was to improve the performance of HSA by various forms of overhead reduction, including faster context switching (something GPUs have always been poor at) and even GPU pre-emption. All of this would fit under the umbrella of “improved compute task scheduling” in AMD’s roadmap, though to be clear with AMD meeting us half-way on the architecture side means that they aren’t getting this detailed this soon.
Meanwhile GCN 1.2’s other instruction set improvements are quite interesting. The description of 16-bit FP and Integer operations is actually very descriptive, and includes a very important keyword: low power. Briefly, PC GPUs have been centered around 32-bit mathematical operations for some number of years now since desktop technology and transistor density eliminated the need for 16-bit/24-bit partial precision operations. All things considered, 32-bit operations are preferred from a quality standpoint as they are accurate enough for many compute tasks and virtually all graphics tasks, which is why PC GPUs were limited to (or at least optimized for) partial precision operations for only a relatively short period of time.
However 16-bit operations are still alive and well on the SoC (mobile) side. SoC GPUs are in many ways a 5-10 year old echo of PC GPUs in features and performance, while in other ways they’re outright unique. In the case of SoC GPUs there are extreme sensitivities to power consumption in a way that PCs have never been so sensitive, so while SoC GPUs can use 32-bit operations, they will in some circumstances favor 16-bit operations for power efficiency purposes. Despite the accuracy limitations of a lower precision, if a developer knows they don’t need the greater accuracy then falling back to 16-bit means saving power and depending on the architecture also improving performance if multiple 16-bit operations can be scheduled alongside each other.
Imagination's PowerVR Series 6XT: An Example of An SoC GPU With FP16 Hardware
To that end, the fact that AMD is taking the time to focus on 16-bit operations within the GCN instruction set is an interesting one, but not an unexpected one. If AMD were to develop SoC-class processors and wanted to use their own GPUs, then natively supporting 16-bit operations would be a logical addition to the instruction set for such a product. The power savings would be helpful for getting GCN into the even smaller form factor, and with so many other GPUs supporting special 16-bit execution modes it would help to make GCN competitive with those other products.
Finally, data parallel instructions are the feature we have the least knowledge about. SIMDs can already be described as data parallel – it’s 1 instruction operating on multiple data elements in parallel – but obviously AMD intends to go past that. Our best guess would be that AMD has a manner and need to have 2 SIMD lanes operate on the same piece of data. Though why they would want to do this and what the benefits may be are not clear at this time.








86 Comments
View All Comments
mczak - Wednesday, September 10, 2014 - link
This is only partly true. AMD cards nowadays can stay at the same clocks in multimon as in single monitor mode though it's a bit more limited than GeForces. Hawaii, Tonga can keep the same low clocks (and thus idle power consumption) up to 3 monitors, as long as they all are identical (or rather more accurately probably, as long as they all use the same display timings). But if they have different timings (even if it's just 2 monitors), they will clock the memory to the max clock always (this is where nvidia kepler chips have an advantage - they will stay at low clocks even with 2, but not 3, different monitors).Actually I believe if you have 3 identical monitors, current kepler geforces won't be able to stick to the low clocks, but Hawaii and Tonga can, though unfortunately I wasn't able to find the numbers for the geforces - ht4u.net r9 285 review has the numbers for it, sorry I can't post the link as it won't get past the anandtech forum spam detector which is lame).
Solid State Brain - Thursday, September 11, 2014 - link
A twin monitor configuration where the secondary display is smaller / has a lower resolution than the primary one is a very common (and logic) usage scenario nowadays and that's what AMD should sort out first. I'm positively surprised that on newer Tonga GPUs if both displays are identical frequencies remain low (according to the review you pointed out), but I'm not going to purchase a different display (or limit my selection) to get advantage of that when there's no need to with equivalent NVidia GPUs.mczak - Thursday, September 11, 2014 - link
Fixing this is probably not quite trivial. The problem is if you reclock the memory you can't honor memory requests for display scan out for some time. So, for single monitor, what you do is reclock during vertical blank. But if you have several displays with different timings, this won't work for obvious reasons, whereas if they have identical timings, you can just run them essentially in sync, so they have their vertical blank at the same time.I don't know how nvidia does it. One possibility would be a large enough display buffer (but I think it would need to be in the order of ~100kB or so, so not quite free in terms of hw cost).
PEJUman - Thursday, September 11, 2014 - link
I used multimonitor with AMD & NVIDIA cards. I would take that 30W hit if it means working well.NVIDIA: too aggressive with low power mode, if you have video on one screen & game on the other, it will remain at the clock speed of the 1st event (if you start the video before the game loading, it will be stuck at the video clocks).
I used 780TI currently, R9 290x I had previously works better where it will always clock up...
hulu - Wednesday, September 10, 2014 - link
The conclusions section of Crysis: Warhead seems to be copy-pasted from Crysis 3. R9 285 does not in fact trail GTX 760.thepaleobiker - Wednesday, September 10, 2014 - link
@Ryan - A small typo on the last page, last line of first paragraph - "Functionally speaking it’s just an R9 285 with more features"It should be R9 280, not 285. Just wanted to call it out for you! :)
Bring on more Tonga, AMD!
FriendlyUser - Wednesday, September 10, 2014 - link
I would like to note that if memory compression is effective, it should not only improve bandwidth but also reduce the need for texture memory. Maybe 2GB with compression is closer to 3GB in practice, at least if the ~40% compression advantage is true.Obviously, there is no way to predict the future, but I think your conclusion concerning 2GB boards should take compression in account.
Spirall - Wednesday, September 10, 2014 - link
If GCN1.2 (instead of a GCN 2.0) is what AMD has to offer as the new arquitecture for their next year cards, Maxwell (based in 750Ti x 260X tests), will punch hard AMD in terms of performance per watt and production cost (not price) so their net income.shing3232 - Wednesday, September 10, 2014 - link
750ti use a better 28nm process call HPM while rest of the 200 series use HPL , that's the reason why maxwell are so efficient.Spirall - Wednesday, September 10, 2014 - link
I'm afraid this won't be enough (but hope it does). Anyway, as Nvidia is expected to launch their Maxwell 256 bits card nearby, we'll have the answer soon.