A Look at Altera's OpenCL SDK for FPGAs
by Rahul Garg on October 9, 2013 8:00 AM ESTOpenCL Programming Model and Suitability for FPGAs
OpenCL is an open-standard programming interface developed by the Khronos group designed particularly for parallel and heterogeneous computing. OpenCL can be used to program various types of hardware including CPUs, GPGPUs, FPGAs and many-core coprocessors like Xeon Phi or Adapteva's Epiphany. Each hardware vendor that wants its hardware to be exposed to OpenCL needs to provide an OpenCL driver for its hardware. For example, OpenCL drivers are available for various CPUs and GPUs for Windows, Linux and Mac and Altera is now providing OpenCL drivers and associated development tools for their FPGAs. Prior to OpenCL, there were no standard programming languages that exposed coprocessors on an equal footing. Thanks to the rise of GPGPU, the idea of accelerators and coprocessors has entered the mainstream and having a standard interface to accelerators is a big win for FPGA vendors. In many ways, the concepts that apply to programming a discrete GPGPU placed on a PCIe board also apply to FPGAs.
We go over some OpenCL terminology.
Host and devices: The CPU is called the host, and each hardware that has an OpenCL driver is called a device. Each device can have one or more compute units and each compute unit can have multiple processing element. This is shown visually below (figure from Hands on OpenCL course).
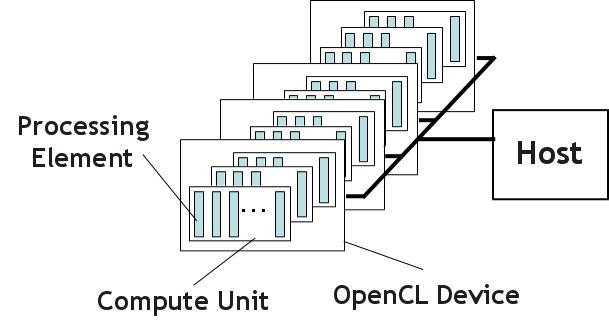
For example, Nvidia Titan GPU contains 15 SMX units and each SMX unit corresponds to a compute unit in OpenCL and each SMX has 192 processing elements. On FPGAs, the number and complexity of each compute unit is not fixed and instead is customized to your application.
Unlike say C, C++, Java or Python, OpenCL cannot be used standalone. Instead, the main program runs on the CPU (the host) as usual and typically only the computationally intensive parts of the program are written in OpenCL and called from the main program. However, work is not automatically distributed across various devices. Instead, the application program can query the OpenCL runtime for the list of all OpenCL compatible devices in a system and can choose the appropriate device for each computation.
Device memory: Each device has its own memory space where it can allocate arrays of data (called buffers) that can be read/written from OpenCL programs. In a discrete GPU or an FPGA, the buffer objects will typically reside in the RAM placed on the PCIe based board that contains the GPU or FPGA chip. For example, in a GPU such as Radeon 7970, the buffer objects will typically be placed in the GDDR5 RAM. OpenCL provides functions to copy data between host (CPU) memory and device memory. Some vendors also allow transferring data between multiple devices in a system directly without CPU intervention.
Kernels: OpenCL programs consist of kernels, which are similar to functions in C. Kernels can read/write from buffer objects that are passed as arguments to the kernel. Kernels are written in a C-like programming language. The OpenCL driver for a given hardware compiles it to the appropriate format. For CPUs and GPUs, the vendor's OpenCL driver will compile it to the native instruction set of the processor. We will get into how kernels are compiled by Altera's SDK in the next section.
Work-items, work-groups and parallelism: Unlike say C, where usually a function call leads to execution of a single instance of a function, the host launches the kernels across a 1D, 2D or 3D grid of "work-items". Each work-item can be thought of a conceptual thread and each work-item executes the same kernel function. However, each work-item knows its index in the thread and will typically compute different parts of a solution.
For example, let us say you wanted to add two vectors of length N. This is how you will do it in plain C:

You can write a kernel where each work-item adds one element of the vector corresponding to its index. Here is the sample OpenCL kernel.

In this case, each work-item is performing the work done by one loop iteration in the C code. Thus, if you wanted to add vectors of size 1000, you will launch this kernel with 1000 parallel work-items. OpenCL is an inherently parallel API and particularly suited for highly parallel problems.
Work-items are organized into work-groups, which are small grids of say 8x8 work-items, and items within a work-group can synchronize with each other but items from different work-groups cannot. This work-item and work-group organization maps particularly well to GPUs. FPGAs also prefer highly parallel workloads but the way they get compiled to FPGAs is very different and we will get to that soon.
Local memory: Accessing memory is an expensive operation. CPUs include hardware-managed caches with the hope that the data that is reused in the program can be brought into the cache once and then read/written multiple times from the cache. However, some architectures such as all recent desktop GPUs from AMD, Nvidia and Intel include small amount of fast memory on-chip that acts as a software managed cache. OpenCL provides a construct called "local memory" to expose such software managed caches. Each work-group can allocate local memory (typically upto 32 or 64kB per work-group) and all work-items in the work-group can read/write from the local memory. Local memory is implemented via the software managed cache on GPUs while CPUs allocate it in regular RAM and hope that it will be end up in the cache during program execution. FPGAs also include on-chip memory that can be used to implement OpenCL's local memory construct in hardware. Some members of the Stratix V series include upto 52Mbit (~6.5MB) of on-chip memory that can be used as local memory. In comparison, Radeon HD 7970 includes about 2MB of local memory on-chip and a GTX Titan includes about 450kB of local memory.
You can learn more about OpenCL at the official page at Khronos or look over some tutorials such as the recently released Hands on OpenCL. Overall, the OpenCL programming model looks to be a surprisingly good fit for FPGAs. Concepts such as host/device separation, device memory vs CPU memory, inherently parallel programming model and finally the local memory abstraction all look to be very well suited to FPGAs.








56 Comments
View All Comments
ET - Tuesday, October 15, 2013 - link
Thanks. That's enlightening. Doesn't support a lot of stuff. (And the table is on page 22 in the document I found.)jarjarbink - Tuesday, February 25, 2014 - link
Can you point a link to the document ?DonnaCabel16 - Monday, October 14, 2013 - link
my Aunty Aaliyah just got an awesome 9 month old Audi allroad Wagon by working parttime from the internet... pop over to this web-site ℰxit35.commike8675309 - Monday, October 14, 2013 - link
I've been following FPGA's for the past 9 months or so and have also been stymied by the costs. Most recently I have been following the development of the Parallella which was a kickstarter project "supercomputer on a chip" development board. While not exactly a FPGA, it does have supporting Zynq-7000 Series Dual-core ARM A9 that has FPGA logic. And the main chip contains 16 cores that can operate concurrently on shared or different workloads. Not very mature for development yet, but OpenCL is one of the languages being targeted for it.0xc000005 - Saturday, October 19, 2013 - link
You didn't mention (afaict) one of the big benefits of using FPGAs - they require much less power (~ 10x less) than GPUs for the same amount of computation. Some readers may find this useful if they want to do gigantic computations under some type of cost constraint. Bitcoin miners moved from GPUs to FPGAs long ago since the cost of electricity is an important factor in Bitcoin mining.OpenCL isn't the only game in town for programming FPGAs either. Xilinx (Altera's main competitor) has a nice product called Vivado High-Level Synthesis where you can write your algorithms in C++. Whether this is a benefit or not remains to be seen - it's harder to design parallel algorithms in C++ than in OpenCL. It's important to be aware that there are a lot of algorithms that are not massively parallel, for which GPUs and OpenCL offer no speedup. This is where C++ is useful, since Vivado can take your sequential, easy-to-simulate algorithm and still make it N times faster - the value of N depends on your algorithm of course.
More about which algorithms can be speeded up using OpenCL can be found at http://www.hpcwire.com/hpcwire/2013-10-14/reprisin...
chaos215bar2 - Sunday, October 20, 2013 - link
Use of local memory in OpenCL generally also requires some kind of synchronization between the threads in a workgroup, as the entire point is to share information between these threads. (A basic example is loading some data into local memory so that all threads can operate on it. A synchronization point is necessary to ensure that all threads have loaded the data they're responsible for before any others attempt to use it.)I'm curious how Altera handles this, since it doesn't map to the pipeline model you described in an obvious way. If, for instance, there's only room for n instances (via vectorization or replication) of the pipeline on the FPGA, does that mean the workgroup size is n? If not, how is the state of one thread saved while waiting for others to reach the synchronization point, and then subsequently restored?