A Look at Altera's OpenCL SDK for FPGAs
by Rahul Garg on October 9, 2013 8:00 AM EST
Efficiency vs flexibility is one of the fundamental tradeoffs in any engineering discipline and it is true in computer architecture as well. For any given task, for example video decode, dedicated hardware is a more power-efficient solution than writing a software decoder that runs on a general purpose processor such as the CPU, or even a GPU's SIMD arrays. Chips designed for a specific purpose are called Application Specific ICs or ASICs. However, designing and manufacturing ASICs is obviously difficult and once a chip is deployed, you cannot use the dedicated silicon area to anything else.
FPGAs, or field programmable gate arrays, fall somewhere between general purpose processors such as CPUs and ASICs in the spectrum of programmability and efficiency. FPGAs consist of a large array of logic blocks and memory cells. The logic blocks are typically small programmable lookup tables that can be used to compute simple logic functions. The connections between the cells are also reconfigurable. Multiple programmable logic blocks and the connections can be configured to create more complex units such as ALUs.
You can utilize the reconfigurability of the FPGA to convert it into a computing device specialized for your application. For example, consider an algorithm that is only performing certain types of integer arithmetic. In this case, you can reconfigure the FPGA to act as a large set of integer ALUs with support for the integer operations needed by your application. There is no need to waste any logic cells on floating point logic, and further the integer ALU can be custom for your application instead of a generic unit. Thus, for some applications, an FPGA implementation can often offer much higher performance/watt than a CPU or a GPU implementation of the same algorithm. The efficiency of FPGAs comes partly from the fact that the hardware is reconfigured for your application.
In turn, the integer units in your FPGA will likely not be as efficient (power or area-wise) as an ASIC specifically designed and optimized for your application. However, unlike an ASIC, if you decide to tweak your algorithm in the future, you can simply reflash your FPGA with the new program rather than going to the drawing board again to design, validate and manufacture new ASICs while throwing out the old ones. Some FPGAs even allow for dynamic partial reconfiguration, where one part of the FPGA is reprogrammed while the other part is still active.
However, programming FPGAs has traditionally been difficult and requires expertise in specialized "hardware description languages" (HDLs) like VHDL or Verilog. Some other options, such as SystemC, have also remained somewhat niche. There has been considerable interest in easier tools for programming FPGAs and this is where OpenCL comes in. OpenCL is considerably easier to learn and use than tools like VHDL and Verilog thus addressing one of the traditional weakenesses of FPGAs. Further, there is already university courses and industrial workshops teaching heterogeneous programming concepts in OpenCL or similar languages like CUDA or C++ AMP and thus the number of programmers familiar with OpenCL concepts is increasing quite rapidly.
While experts will likely continue using HDLs, OpenCL will enable many more programmers to use FPGAs. Even HDL experts may use OpenCL as a quick way to prototype their ideas on an FPGA. Interestingly, Xilinx (the biggest FPGA vendor currently) has recently also announced that they are working to bring OpenCL for their FPGAs in the future but no timeline has been announced. In this article we are looking at Altera's OpenCL offering which is already available and shipping. I will add one caveat before proceeding further. My own expertise and experience is primarily in using OpenCL (and similar APIs) on GPUs and CPUs, and not in FPGA or HDLs. You can think of this article as CPU/GPU programmer's view of the FPGA world. I don't have first-hand experience with Altera's SDK yet. This article is based upon my reading of the Altera documentation and whitepapers as well as various FPGA related literature around the web. The folks from Altera were also a big help for this article, as they were able to get answers for many of my questions.
Altera's Products and Roadmap
Altera designs and manufactures FPGA chips and these chips are then sold to partners and clients. CPU and GPU companies typically have multiple products differing in specificatons such as number of cores, frequency, features, memory interfaces etc. Similarly, Altera offers multiple product lines and multiple products within each line. Products are differentiated along specifications such as the number of adaptive logic modules (ALMs), the type and size of on-chip memory and external I/O bandwidth. FPGA vendors have also started including some additional programmable processors on-chip. For example, some of Altera's Stratix V FPGAs integrate DSP blocks on chip and Cyclone V FPGAs integrate ARM CPU cores on-chip. FPGAs may also have high-speed transceivers on-chip to connect to external I/O devices such as video cameras, medical imaging devices, network devices and high-speed storage devices. Networking and high-speed streaming/filtering type applications are particularly suited for such devices.
A block diagram of Altera's Stratix V FPGA (source) showing the core logic fabric with logic blocks and interconnects, on-chip memory (m20k blocks), DSP blocks, transceivers and other I/O interfaces is shown below:
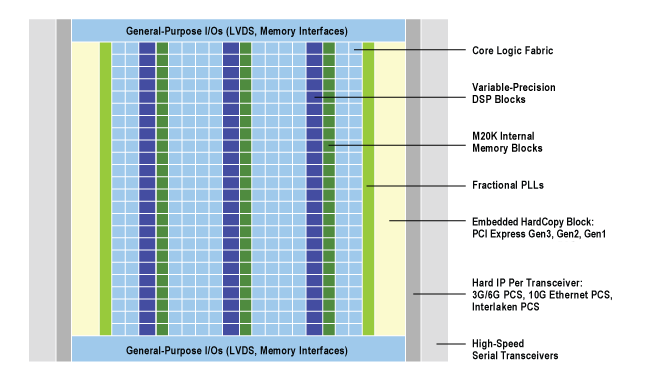
Altera partners will design a product, for example a PCIe based board, around the FPGA and may add their own customizations such as I/O interfaces supported on the board, peripherals as well as the size and bandwidth of associated onboard memory (if any). PCIe based boards are far from the only way to deploy FPGAs and some customers may choose a custom solution. However, we will focus on the PCIe based use case for this article.
Altera's current generation high-end product line is under the brand Stratix V and is currently their only product series to support OpenCL. Stratix V series is currently built on a 28nm process at TSMC. Interestingly, FPGA manufacturs are typically one of the first products to adopt new process technologies. Altera's 28nm products started shipping well before the first 28nm GPUs or mobile CPUs. Altera has also announced 20nm products (branded Arria 10). Significantly, Altera has announced a deal with Intel to fabricate their upcoming Stratix 10 branded 14nm FPGAs in Intel's manufacturing facilities.
Altera introduced a private beta for OpenCL on FPGAs late last year. The SDK has now been made public. Altera's implementation is built on top of OpenCL 1.0 but offers custom extensions to tap into the unique features of FPGAs. More information can be found on Altera's OpenCL page. They are also adopting some features, such as pipes, from the OpenCL 2.0 provisional spec. From a performance standpoint, Altera has posted whitepapers where they show that FPGAs offer much higher performance/watt on some applications compared to CPUs and GPUs. Typical FPGA board power used in Altera's studies is somewhere in the range of 20W which is much lower than the high-end discrete GPUs such as Tesla series GPUs which are often in the 200W range. Altera claims that OpenCL running on an FPGA will either outperform the GPU or match its performance at considerably lower power on some applications. Altera does not claim that this will be true for every application but I do think it is a reasonable claim for some types of applications.
We will go into some OpenCL terminology and how the concepts map to FPGAs. Next we will look at some details of Altera's OpenCL implementation and finally I will offer some concluding remarks.








56 Comments
View All Comments
kishonti - Wednesday, October 9, 2013 - link
We've tested Altera's OpenCL SDK : https://twitter.com/KishontiI/status/3647712482716...Most of the more complex tests (with multiple kernels) had size issues to fit on the chip. As compilation takes literally hours, the compile/debug cycles are much harder to manage.
rahulgarg - Wednesday, October 9, 2013 - link
Thanks for the extremely informative datapoints!Todd Thompson - Wednesday, October 9, 2013 - link
kishonti, thanks for posting/tweeting about your benchmark...you mention a long compile time...is this something that you think could be pushed to the cloud and compiled on more robust hardware...if so, is this something that you would actually do? I might be able to help if you are interested...thanks againkishonti - Wednesday, October 9, 2013 - link
Currently the OpenCL SDK runs within Altera's Quartus toolchain, so I don't think it is possible to run this in cloud. We used a relatively powerful 2 x 8 core Xeon workstation, but the compile process did not scale much - used 1 or 2 cores most of the time.Obviously we tested the code first on GPUs and CPUs (hundreds of them, actually) but it was still a trial and error process because only after several hours of number crunching we get the info that our kernel fits or not. This could be still faster than building a VHDL model from scratch...
Jaybus - Thursday, October 10, 2013 - link
It is a decision problem, similar to the problem of routing traces on a chip such that the length of the longest trace is minimized, also known as the traveling salesman problem. So it belongs to a class of problems known as NP-complete. The NP stands for Non-deterministic Polynomial time. We express the complexity of most algorithms using "Big O" terminology, but we can not do so for these problems due to their non-deterministic nature. Actually, whether or not it is even possible to solve these problems quickly is one of the principle unsolved problems of computer science. I'm not saying that the compiler doesn't come up with a correct solution, only that it must do so basically by brute force trial and error. Deterministic problems can be broken into independent parts and processed in parallel. Not so for non-deterministic problems, and so it doesn't scale.That said, it is possible to break it into parts, calculate in parallel, then check for conflicts. If a conflict is found, throw that one out and repeat until you find one without conflicts. There still is no way to determine if it is optimal, but you can repeat the process until you find N solutions and pick the best one. Currently, trial and error is the best solution. It could even be the only solution. Some very smart people are working on the problem, but nobody has a solution yet.
Alexey.Martin - Friday, November 8, 2013 - link
kishonti, do you have any actual results from Altera's OpenCL testing?chowyuncat - Wednesday, October 9, 2013 - link
Is it viable to iteratively test on a GPU and only compile once at the end for an FPGA?dneto - Wednesday, October 9, 2013 - link
Yes. See another of my comments.tuxfool - Wednesday, October 9, 2013 - link
Not really. The gpu is running software. A FPGA, however is effectively generating hardware to process a particular algorithm.The generation of this hardware is subject to a great deal of optimization in terms of clock signals available, availability of logic cells etc.
tuxfool - Wednesday, October 9, 2013 - link
well, apparently you can. But what happens when your program uses a kernel that is unsynthesizable in the users FPGA? Any further iteration will need to be done using the FPGA....right?