Intel Whittles Down AI Portfolio, Folds Nervana in Favor of Habana
by Ryan Smith on February 3, 2020 10:00 PM EST
Over the past several years, Intel has built up a significant portfolio of AI acceleration technologies. This includes everything from in-house developments like Intel’s DL Boost instructions and upcoming GPUs, to third party acquisitions like Nervana, Movidius, and most recently, Habana labs. With so many different efforts going on it could be argued that Intel was a little too fractured, and it would seem that the company has come to the same conclusion. Revealed quietly on Friday, Intel will be wrapping up its efforts with Nervana’s accelerator technology in order to focus on Habana Labs’ tech.
Originally acquired by Intel in 2016, Nervana was in the process of developing a pair of accelerators for Intel. These included the “Spring Hill” NNP-I inference accelerator, and the “Spring Crest” NNP-T training accelerator. Aimed at different markets, the NNP-I was Intel’s first in-house dedicated inference accelerator, using a mix of Intel Sunny Cove CPU cores and Nervana compute engines. Meanwhile NNP-T would be the bigger beast, a 24 tensor processor chip with over 27 billion transistors.

But, as first broken by Karl Freund of Moore Insights, Spring won’t be arriving after all. As of last Friday, Intel has decided to wrap up their development of Nervana’s processors. Development of NNP-T has been canceled entirely. Meanwhile, as NNP-I is a bit further along and already has customer commitments, that chip will be delivered and supported by Intel for their already committed customers.
In place of their Nervana efforts, Intel will be expanding their efforts on a more recent acquisition: Habana Labs. Picked up by Intel just two months ago, Habana is an independent business unit that has already been working on their own AI processors, Goya and Gaudi. Like Nervana’s designs, these are intended to be high performance processors for inference and training. And with hardware already up and running, Habana has already turned in some interesting results on the first release of the MLPerf inference benchmark.

In a statement issued to CRN, Intel told the site that "Habana product line offers the strong, strategic advantage of a unified, highly-programmable architecture for both inference and training," and that "By moving to a single hardware architecture and software stack for data center AI acceleration, our engineering teams can join forces and focus on delivering more innovation, faster to our customers."
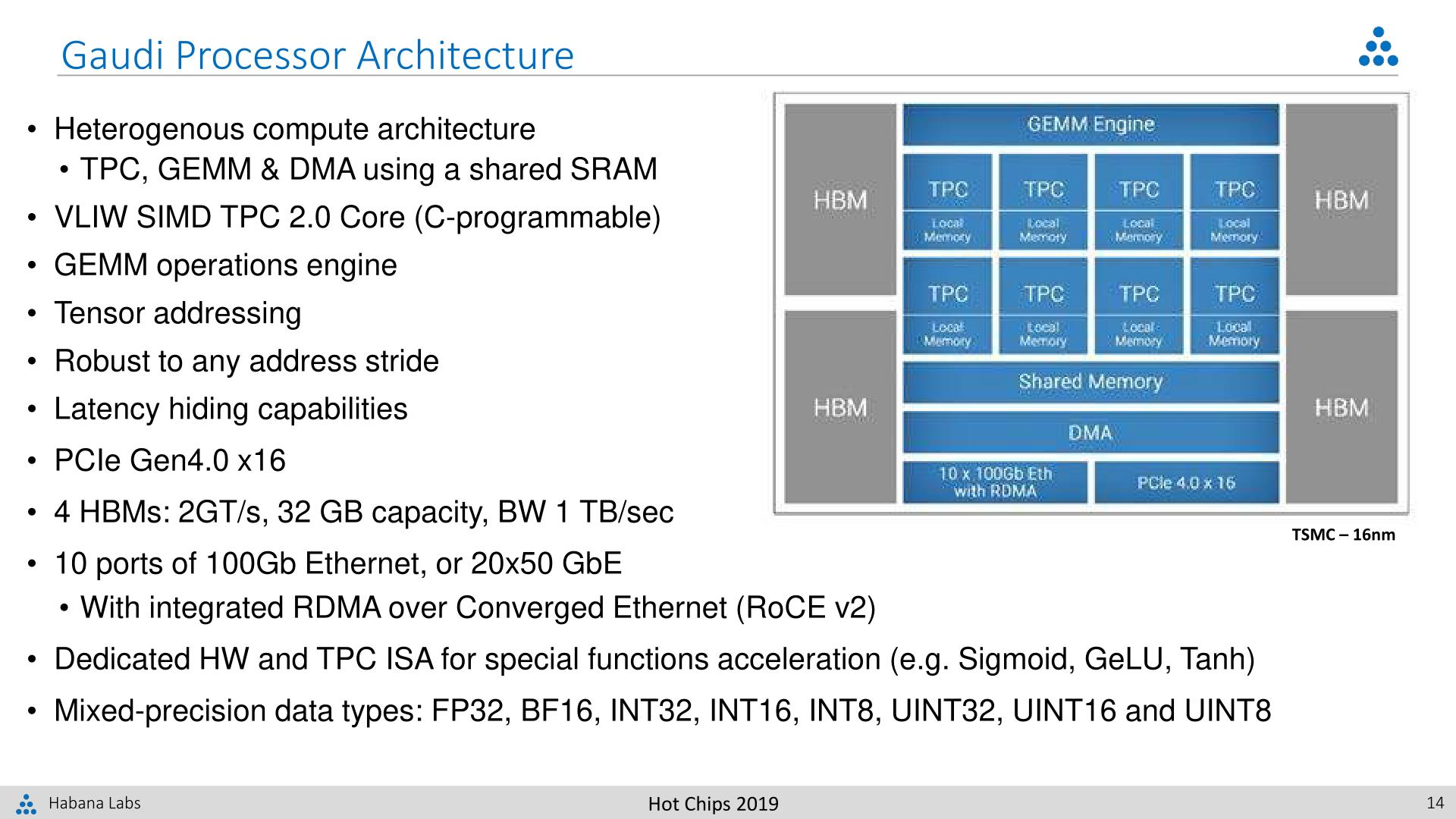
Large companies running multiple, competitive projects to determine a winner is not unheard of, especially for early-generation products. But in Intel’s case this is complicated by the fact that they’ve owned Nervana for a lot longer than they’ve owned Habana. It’s telling, perhaps, that Nervana’s NNP-T accelerator, which had never been delivered, was increasingly looking last-generation with respect to manufacturing: the chip was to be built on TSMC’s 16nm+ process and used 2.4Gbps HBM2 memory at a time when competitors are getting ready to tap TSMC’s 7nm process as well as newer 3.2Gbps HBM2 memory.
According to CRN, analysts have been questioning the fate of Nervana for a while now, especially as the Habana acquisition created a lot of overlap. Ultimately, no matter the order in which things have occurred, Intel has made it clear that it’s going to be Habana and GPU technologies backing their high-end accelerators going forward, rather than Nervana’s tech.
As for what this means for Intel’s other AI projects, this remains to be seen. But as the only other dedicated AI silicon comes out of Intel’s edge-focused Movidius group, it goes without saying that Movidius is focused on a much different market than Habana or the GPU makers of the world that Intel is looking to compete with at the high-end. So even with multiple AI groups still in-house, Intel isn’t necessarily on a path to further consolidation.
Source: Karl Freund (Forbes)








42 Comments
View All Comments
m53 - Tuesday, February 4, 2020 - link
"Nvidia finest AI chip, the V100 GPU, manages something over 3,247 images/second at 2.5ms latency (which drops to 1,548 images/second if it wants to match Goya’s self-reported 1.3ms latency)."https://www.nextplatform.com/2019/01/28/ai-chip-st...
"Two Nervana NNP-I chips achieve 10,567 inputs per second in ResNet-50, according to third-party benchmarks. Within the same power bracket, one Habana Goya reaches 14,451 inputs per second."
https://www.techspot.com/news/83826-intel-sacrific...
p1esk - Wednesday, February 5, 2020 - link
Unlike Nervana/Havana V100 can do a lot more than deep learning, considering its FP64 capability.mode_13h - Wednesday, February 5, 2020 - link
True. Also, the tensor cores in the Turing series can do int8 inferencing at double the throughput of the V100's, which are fp16-based.I think Nvidia's bread-and-butter GPU for cloud-based inferencing is the TU104-based Tesla T4 - not the V100.
mode_13h - Wednesday, February 5, 2020 - link
BTW, I know the Turing Tensor cores can *also* do fp16, but the V100's Tensor cores can't do int8.m53 - Thursday, February 6, 2020 - link
@p1esk: Well CPUs are way more flexible than a GPU but still there is a big market for GPU for the better perf/watt in highly parallel workloads like graphics processing, game streaming, etc. Similarly AI chips are specialized in AI workloads and perform much better for same power usage than a GPU. Many hyperscalers are currently using Nvidia GPUs for such AI workloads since there wasn't many choice for dedicated AI hardware. Facebook is a good example which currently use Nvidia GPUs for AI workloads like face detection and tagging but now looking for dedicated AI hardware. Google used to use Nvidia hardware for AI inference but has moved to TPUs. So yes, dedicated AI hardware has a big market where flexibility doesn't matter. That's the target market for these Habana chips.p1esk - Friday, February 7, 2020 - link
That's a good point, if you're talking about hardware only. However, the software aspect is just as important, and as far as software, Nvidia is far ahead of competition. Google is well positioned because it already had a popular DL software platform (Tensorflow), so it made sense for them to build its own hardware, targeting their software. Intel has a much harder task - it needs to earn trust, meaning that not only it must produce much faster hardware than competition (Tesla Ampere), it must also deliver rock solid DL frameworks support for its cards, and somehow I'm not holding my breath. "Slightly faster" cards than Nvidia coupled with mediocre software is just not gonna fly.mode_13h - Friday, February 7, 2020 - link
Look at how much of a TU104 die is occupied with Raytracing cores and other GPU-specific hardware blocks. Among other things, this overhead makes Nvidia more expensive (unless they decide to fab a chip without it, that's just tensor + CUDA cores).mode_13h - Friday, February 7, 2020 - link
And NVDEC blocks - one benefit GPUs have over most AI chips is hardware-acceleated decoding.m53 - Sunday, February 9, 2020 - link
"Google is well positioned because it already had a popular DL software platform (Tensorflow)" --> Well tensorflow is open source. So others can use it too.""Slightly faster" cards than Nvidia coupled with mediocre software is just not gonna fly." --> Agreed. But from the benchmarks it is not slightly faster. It is order of magnitude faster for same watt and I expect it to be far cheaper since it doesn't have any extra unused hardware. Also AI is a nascent market. It will evolve drastically in the next few years. The software situation will also change dramatically. I don't see a general purpose GPU to keep lion's share in this evolving market.
mode_13h - Wednesday, February 5, 2020 - link
What's funny about this is that ResNet is pretty small, by comparison with networks that a lot of people are using, these days.However, the really silly thing is that they're comparing at small batch size. Who cares about small batch size? Realtime/embedded (i.e. robotics, self-driving, etc.) - not cloud. AFAIK, Habana's products are all aimed at the cloud. In the cloud, you're dealing with big enough flows of data that you can afford a decent batch size, making that comparison fairly unrealistic.