ARM Unveils Next Generation Bifrost GPU Architecture & Mali-G71: The New High-End Mali
by Ryan Smith on May 30, 2016 7:00 AM EST
Over the last few years the SoC GPU space has taken an interesting path, and one I admittedly wasn’t expecting. At the start of this decade the playing field for SoC-class GPUs was rather diverse, with everyone from NVIDIA to Broadcom (and everything in between) participating in it. Consolidation in the GPU space would be inevitable – something we’ve already seen with SoC vendors dropping out – however I am surprised by just how quickly it has happened. In just six years, the number of GPU vendors with a major presence in high-end Android phones has been whittled down to only two: the vertically integrated Qualcomm, and the IP-licensing ARM.
That ARM has managed to secure most of the licensed GPU market for themselves is a testament to both their engineering and their IP licensing efforts. ARM’s path into this market has been non-traditional, having acquired an essentially unknown GPU vendor a decade ago, and growing it into the 800lb gorilla it has now become. ARM’s expertise in IP licensing, coupled with a somewhat unusual GPU architecture, has proven to be a powerful combination for the company as they have secured a number of significant wins from the high end to the low end.
Much of this growth was built on the back of the company’s GPU architecture of the last few years, Midgard. Initially launched in 2012, Midgard has been the cornerstone of ARM’s Mali 600, 700, and 800 series designs. As ARM’s first unified shader design for GPUs, Midgard has been extended over the years to support newer features such as geometry tessellation and 10bpc color, along with newer APIs such as OpenGL ES 3.1/3.2 and Vulkan.
However as Midgard approaches its fourth birthday and the SoC GPU landscape evolves, Midgard’s time at the top will soon be coming to an end. Amidst the backdrop of Computex 2016 and alongside their new Cortex-A73 CPU, ARM is announcing their next generation GPU architecture, Bifrost. A significant update to ARM’s GPU architecture, Bifrost will first be deployed in ARM’s Mali-G71 GPU.

Recap: Mali & VLIW
One of the interesting aspects of SoC GPU development over the years is that it has been a very distinct echo of larger discrete GPU development. Many innovations and changes that first show up with dGPUs will show up in SoC GPUs a few years later, as newer manufacturing processes allow for those developments to fit within the extreme space and power requirements of an SoC-class GPU. At the same time mobile games/graphics development follows a similar path, with mobile application developers picking up rendering techniques first used elsewhere.
ARM’s architectural development, in turn, has been a good example of this process. The non-unified Utgard architecture gave way to the unified Midgard architecture in 2012, about 6 years after dGPUs first made the transition. And as we learned when we examined the Midgard architecture in depth, Midgard was an architecture well suited for the rendering paradigms of the time.
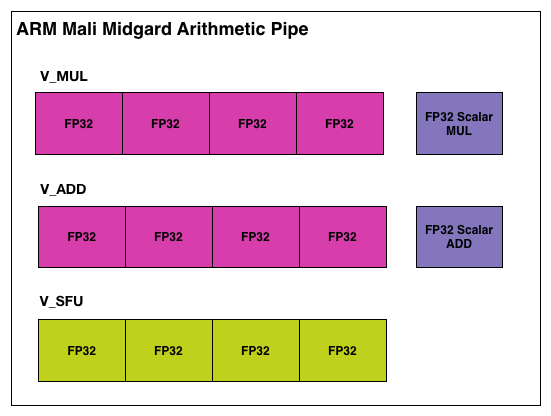
Midgard’s shader core, in short, was an Instruction Level Parallelism-centric design, employing a Very Long Instruction Word (VLIW) instruction format. To achieve maximum utilization out of Midgard’s shader cores, you needed to be able to extract a significant amount of ILP – 4 concurrent instructions – in order to fill all of the slots in a shader core. This sort of design maps well to basic graphics workloads, as 4 color component RGBA is a natural fit for the 4 lanes of ARM’s VLIW-4 design. Furthermore VLIW designs are traditionally very space efficient, as there’s relatively little overhead logic, which is always a boon for the tight constraints of the SoC space.
However getting back to what we said earlier about SoC GPUs being an echo of discrete GPUs, as we’ve seen there, VLIW does have a limited shelf life. Newer rendering paradigms often work with just 1 or 2 components at once, which leaves open lanes that need to be filled to achieve full GPU utilization. A good shader compiler can help here, but it does become an escalating technology war over time, as getting good performance becomes increasingly compiler-centric, and writing a compiler that can extract the necessary ILP is a challenge in and of itself. What history has shown us – and what is going to happen again in the mobile market – is that rendering workloads will continue to shift away from a style that is suitable for VLIW.








57 Comments
View All Comments
mosu - Tuesday, May 31, 2016 - link
What is really meaningful for me is that ARM is confirming the validity of AMD approach of heterogenous computing and graphic processing.I wonder why ARM didn't emulate nVidia and if they did try what were the results?mkozakewich - Tuesday, May 31, 2016 - link
Ermagerd, intergers!TheFrisbeeNinja - Wednesday, June 1, 2016 - link
Love this article; well done. This one and the A73 one (http://www.anandtech.com/show/10347/arm-cortex-a73... are the primary reason I continue to visit this site.Scali - Sunday, June 5, 2016 - link
"This is a very similar transition to what AMD made with Graphics Core Next in 2011, a move that significantly improved AMD’s GPU throughput and suitability for modern rendering paradigms."nVidia already did this in 2006(!) with the GeForce 8800. The main reason was of course CUDA, and nVidia's forward-looking perspective that CUDA would be running different types of workloads than the graphics workloads at the time.
Scali - Sunday, June 5, 2016 - link
See the whitepaper here: http://www.nvidia.co.uk/content/PDF/Geforce_8800/G...lolipopman - Monday, October 3, 2016 - link
What are you trying to prove, exactly? How is this in anyway relevant?NoSoMo - Thursday, June 16, 2016 - link
Bi-Frost huh? Does it teleport you between planets? Did Thor have a hand in this?